Introduction
Spock is a testing and specification framework for Java and Groovy applications. What makes it stand out from the crowd is its beautiful and highly expressive specification language. Thanks to its JUnit runner, Spock is compatible with most IDEs, build tools, and continuous integration servers. Spock is inspired from JUnit, jMock, RSpec, Groovy, Scala, Vulcans, and other fascinating life forms.
Getting Started
It’s really easy to get started with Spock. This section shows you how.
Spock Web Console
Spock Web Console is a website that allows you to instantly view, edit, run, and even publish Spock specifications. It is the perfect place to toy around with Spock without making any commitments. So why not run Hello, Spock! right away?
Spock Example Project
To try Spock in your local environment, clone or download/unzip the Spock Example Project. It comes with fully working Ant, Gradle, and Maven builds that require no further setup. The Gradle build even bootstraps Gradle itself and gets you up and running in Eclipse or IDEA with a single command. See the README for detailed instructions.
Spock Primer
This chapter assumes that you have a basic knowledge of Groovy and unit testing. If you are a Java developer but haven’t heard about Groovy, don’t worry - Groovy will feel very familiar to you! In fact, one of Groovy’s main design goals is to be the scripting language alongside Java. So just follow along and consult the Groovy documentation whenever you feel like it.
The goals of this chapter are to teach you enough Spock to write real-world Spock specifications, and to whet your appetite for more.
To learn more about Groovy, go to https://groovy-lang.org/.
To learn more about unit testing, go to https://en.wikipedia.org/wiki/Unit_testing.
Terminology
Let’s start with a few definitions: Spock lets you write specifications that describe expected features (properties, aspects) exhibited by a system of interest. The system of interest could be anything between a single class and a whole application, and is also called the system under specification or SUS. The description of a feature starts from a specific snapshot of the SUS and its collaborators; this snapshot is called the feature’s fixture.
The following sections walk you through all building blocks of which a Spock specification may be composed. A typical specification uses only a subset of them.
Imports
import spock.lang.*Package spock.lang contains the most important types for writing specifications.
Specification
class MyFirstSpecification extends Specification {
// fields
// fixture methods
// feature methods
// helper methods
}A specification is represented as a Groovy class that extends from spock.lang.Specification. The name of a specification
usually relates to the system or system operation described by the specification. For example, CustomerSpec,
H264VideoPlayback, and ASpaceshipAttackedFromTwoSides are all reasonable names for a specification.
Class Specification contains a number of useful methods for writing specifications. Furthermore it instructs JUnit to
run specification with Sputnik, Spock’s JUnit runner. Thanks to Sputnik, Spock specifications can be run by most modern
Java IDEs and build tools.
Fields
def obj = new ClassUnderSpecification()
def coll = new Collaborator()Instance fields are a good place to store objects belonging to the specification’s fixture. It is good practice to
initialize them right at the point of declaration. (Semantically, this is equivalent to initializing them at the very
beginning of the setup() method.) Objects stored into instance fields are not shared between feature methods.
Instead, every feature method gets its own object. This helps to isolate feature methods from each other, which is often
a desirable goal.
@Shared res = new VeryExpensiveResource()Sometimes you need to share an object between feature methods. For example, the object might be very expensive to create,
or you might want your feature methods to interact with each other. To achieve this, declare a @Shared field. Again
it’s best to initialize the field right at the point of declaration. (Semantically, this is equivalent to initializing
the field at the very beginning of the setupSpec() method.)
static final PI = 3.141592654Static fields should only be used for constants. Otherwise, shared fields are preferable, because their semantics with respect to sharing are more well-defined.
Fixture Methods
def setupSpec() {} // runs once - before the first feature method
def setup() {} // runs before every feature method
def cleanup() {} // runs after every feature method
def cleanupSpec() {} // runs once - after the last feature methodFixture methods are responsible for setting up and cleaning up the environment in which feature methods are run.
Usually it’s a good idea to use a fresh fixture for every feature method, which is what the setup() and cleanup() methods are for.
All fixture methods are optional.
Occasionally it makes sense for feature methods to share a fixture, which is achieved by using shared fields together with the setupSpec() and cleanupSpec() methods.
Note that setupSpec() and cleanupSpec() may not reference instance fields unless they are annotated with @Shared.
|
Note
|
There may be only one fixture method of each type per specification class. |
Invocation Order
If fixture methods are overridden in a specification subclass then setup() of the superclass will run before setup() of the subclass.
cleanup() works in reverse order, that is cleanup() of the subclass will execute before cleanup() of the superclass.
setupSpec() and cleanupSpec() behave in the same way.
There is no need to explicitly call super.setup() or super.cleanup() as Spock will automatically find and execute fixture methods at all levels in an inheritance hierarchy.
-
super.setupSpec -
sub.setupSpec -
super.setup -
sub.setup -
feature method
-
sub.cleanup -
super.cleanup -
sub.cleanupSpec -
super.cleanupSpec
Feature Methods
def "pushing an element on the stack"() {
// blocks go here
}Feature methods are the heart of a specification. They describe the features (properties, aspects) that you expect to find in the system under specification. By convention, feature methods are named with String literals. Try to choose good names for your feature methods, and feel free to use any characters you like!
Conceptually, a feature method consists of four phases:
-
Set up the feature’s fixture
-
Provide a stimulus to the system under specification
-
Describe the response expected from the system
-
Clean up the feature’s fixture
Whereas the first and last phases are optional, the stimulus and response phases are always present (except in interacting feature methods), and may occur more than once.
Blocks
Spock has built-in support for implementing each of the conceptual phases of a feature method. To this end, feature
methods are structured into so-called blocks. Blocks start with a label, and extend to the beginning of the next block,
or the end of the method. There are six kinds of blocks: given, when, then, expect, cleanup, and where blocks.
Any statements between the beginning of the method and the first explicit block belong to an implicit given block.
A feature method must have at least one explicit (i.e. labelled) block - in fact, the presence of an explicit block is what makes a method a feature method. Blocks divide a method into distinct sections, and cannot be nested.
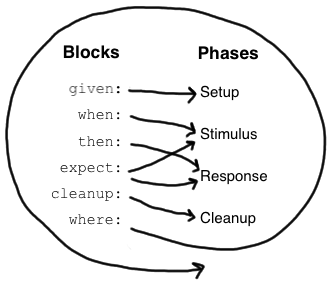
The picture on the right shows how blocks map to the conceptual phases of a feature method. The where block has a
special role, which will be revealed shortly. But first, let’s have a closer look at the other blocks.
Given Blocks
given:
def stack = new Stack()
def elem = "push me"The given block is where you do any setup work for the feature that you are describing. It may not be preceded by
other blocks, and may not be repeated. A given block doesn’t have any special semantics. The given: label is
optional and may be omitted, resulting in an implicit given block. Originally, the alias setup: was the preferred block name,
but using given: often leads to a more readable feature method description (see Specifications as Documentation).
When and Then Blocks
when: // stimulus
then: // responseThe when and then blocks always occur together. They describe a stimulus and the expected response. Whereas when
blocks may contain arbitrary code, then blocks are restricted to conditions, exception conditions, interactions,
and variable definitions. A feature method may contain multiple pairs of when-then blocks.
Conditions
Conditions describe an expected state, much like JUnit’s assertions. However, conditions are written as plain boolean expressions, eliminating the need for an assertion API. (More precisely, a condition may also produce a non-boolean value, which will then be evaluated according to Groovy truth.) Let’s see some conditions in action:
when:
stack.push(elem)
then:
!stack.empty
stack.size() == 1
stack.peek() == elem|
Tip
|
Try to keep the number of conditions per feature method small. One to five conditions is a good guideline. If you have more than that, ask yourself if you are specifying multiple unrelated features at once. If the answer is yes, break up the feature method in several smaller ones. If your conditions only differ in their values, consider using a data table. |
What kind of feedback does Spock provide if a condition is violated? Let’s try and change the second condition to
stack.size() == 2. Here is what we get:
Condition not satisfied:
stack.size() == 2
| | |
| 1 false
[push me]As you can see, Spock captures all values produced during the evaluation of a condition, and presents them in an easily digestible form. Nice, isn’t it?
Implicit and explicit conditions
Conditions are an essential ingredient of then blocks and expect blocks. Except for calls to void methods and
expressions classified as interactions, all top-level expressions in these blocks are implicitly treated as conditions.
To use conditions in other places, you need to designate them with Groovy’s assert keyword:
def setup() {
stack = new Stack()
assert stack.empty
}If an explicit condition is violated, it will produce the same nice diagnostic message as an implicit condition.
Exception Conditions
Exception conditions are used to describe that a when block should throw an exception. They are defined using the
thrown() method, passing along the expected exception type. For example, to describe that popping from an empty stack
should throw an EmptyStackException, you could write the following:
when:
stack.pop()
then:
thrown(EmptyStackException)
stack.emptyAs you can see, exception conditions may be followed by other conditions (and even other blocks). This is particularly useful for specifying the expected content of an exception. To access the exception, first bind it to a variable:
when:
stack.pop()
then:
def e = thrown(EmptyStackException)
e.cause == nullAlternatively, you may use a slight variation of the above syntax:
when:
stack.pop()
then:
EmptyStackException e = thrown()
e.cause == nullThis syntax has two small advantages: First, the exception variable is strongly typed, making it easier for IDEs to
offer code completion. Second, the condition reads a bit more like a sentence ("then an EmptyStackException is thrown").
Note that if no exception type is passed to the thrown() method, it is inferred from the variable type on the left-hand
side.
Sometimes we need to convey that an exception should not be thrown. For example, let’s try to express that a HashMap
should accept a null key:
def "HashMap accepts null key"() {
setup:
def map = new HashMap()
map.put(null, "elem")
}This works but doesn’t reveal the intention of the code. Did someone just leave the building before he had finished implementing this method? After all, where are the conditions? Fortunately, we can do better:
def "HashMap accepts null key"() {
given:
def map = new HashMap()
when:
map.put(null, "elem")
then:
notThrown(NullPointerException)
}By using notThrown(), we make it clear that in particular a NullPointerException should not be thrown. (As per the
contract of Map.put(), this would be the right thing to do for a map that doesn’t support null keys.) However,
the method will also fail if any other exception is thrown.
Interactions
Whereas conditions describe an object’s state, interactions describe how objects communicate with each other. Interactions and Interaction based testing are described in a separate chapter, so we only give a quick example here. Suppose we want to describe the flow of events from a publisher to its subscribers. Here is the code:
def "events are published to all subscribers"() {
given:
def subscriber1 = Mock(Subscriber)
def subscriber2 = Mock(Subscriber)
def publisher = new Publisher()
publisher.add(subscriber1)
publisher.add(subscriber2)
when:
publisher.fire("event")
then:
1 * subscriber1.receive("event")
1 * subscriber2.receive("event")
}Expect Blocks
An expect block is more limited than a then block in that it may only contain conditions and variable definitions.
It is useful in situations where it is more natural to describe stimulus and expected response in a single expression.
For example, compare the following two attempts to describe the Math.max() method:
when:
def x = Math.max(1, 2)
then:
x == 2expect:
Math.max(1, 2) == 2Although both snippets are semantically equivalent, the second one is clearly preferable. As a guideline, use when-then
to describe methods with side effects, and expect to describe purely functional methods.
|
Tip
|
Leverage Groovy JDK methods like any() and every()
to create more expressive and succinct conditions.
|
Cleanup Blocks
given:
def file = new File("/some/path")
file.createNewFile()
// ...
cleanup:
file.delete()A cleanup block may only be followed by a where block, and may not be repeated. Like a cleanup method, it is used
to free any resources used by a feature method, and is run even if (a previous part of) the feature method has produced
an exception. As a consequence, a cleanup block must be coded defensively; in the worst case, it must gracefully
handle the situation where the first statement in a feature method has thrown an exception, and all local variables
still have their default values.
|
Tip
|
Groovy’s safe dereference operator (foo?.bar()) simplifies writing defensive code.
|
Object-level specifications usually don’t need a cleanup method, as the only resource they consume is memory, which
is automatically reclaimed by the garbage collector. More coarse-grained specifications, however, might use a cleanup
block to clean up the file system, close a database connection, or shut down a network service.
|
Tip
|
If a specification is designed in such a way that all its feature methods require the same resources, use a
cleanup() method; otherwise, prefer cleanup blocks. The same trade-off applies to setup() methods and given blocks.
|
Where Blocks
A where block always comes last in a method, and may not be repeated. It is used to write data-driven feature methods.
To give you an idea how this is done, have a look at the following example:
def "computing the maximum of two numbers"() {
expect:
Math.max(a, b) == c
where:
a << [5, 3]
b << [1, 9]
c << [5, 9]
}This where block effectively creates two "versions" of the feature method: One where a is 5, b is 1, and c is 5,
and another one where a is 3, b is 9, and c is 9.
Although it is declared last, the where block is evaluated before the feature method containing it runs.
The where block is further explained in the Data Driven Testing chapter.
Helper Methods
Sometimes feature methods grow large and/or contain lots of duplicated code. In such cases it can make sense to introduce one or more helper methods. Two good candidates for helper methods are setup/cleanup logic and complex conditions. Factoring out the former is straightforward, so let’s have a look at conditions:
def "offered PC matches preferred configuration"() {
when:
def pc = shop.buyPc()
then:
pc.vendor == "Sunny"
pc.clockRate >= 2333
pc.ram >= 4096
pc.os == "Linux"
}If you happen to be a computer geek, your preferred PC configuration might be very detailed, or you might want to compare offers from many different shops. Therefore, let’s factor out the conditions:
def "offered PC matches preferred configuration"() {
when:
def pc = shop.buyPc()
then:
matchesPreferredConfiguration(pc)
}
def matchesPreferredConfiguration(pc) {
pc.vendor == "Sunny"
&& pc.clockRate >= 2333
&& pc.ram >= 4096
&& pc.os == "Linux"
}The new helper method matchesPreferredConfiguration() consists of a single boolean expression whose result is returned.
(The return keyword is optional in Groovy.) This is fine except for the way that an inadequate offer is now presented:
Condition not satisfied:
matchesPreferredConfiguration(pc)
| |
false ...Not very helpful. Fortunately, we can do better:
void matchesPreferredConfiguration(pc) {
assert pc.vendor == "Sunny"
assert pc.clockRate >= 2333
assert pc.ram >= 4096
assert pc.os == "Linux"
}When factoring out conditions into a helper method, two points need to be considered: First, implicit conditions must
be turned into explicit conditions with the assert keyword. Second, the helper method must have return type void.
Otherwise, Spock might interpret the return value as a failing condition, which is not what we want.
As expected, the improved helper method tells us exactly what’s wrong:
Condition not satisfied:
assert pc.clockRate >= 2333
| | |
| 1666 false
...A final advice: Although code reuse is generally a good thing, don’t take it too far. Be aware that the use of fixture and helper methods can increase the coupling between feature methods. If you reuse too much or the wrong code, you will end up with specifications that are fragile and hard to evolve.
Using with for expectations
As an alternative to the above helper methods, you can use a with(target, closure) method to interact on the object being verified.
This is especially useful in then and expect blocks.
def "offered PC matches preferred configuration"() {
when:
def pc = shop.buyPc()
then:
with(pc) {
vendor == "Sunny"
clockRate >= 2333
ram >= 406
os == "Linux"
}
}Unlike when you use helper methods, there is no need for explicit assert statements for proper error reporting.
When verifying mocks, a with statement can also cut out verbose verification statements.
def service = Mock(Service) // has start(), stop(), and doWork() methods
def app = new Application(service) // controls the lifecycle of the service
when:
app.run()
then:
with(service) {
1 * start()
1 * doWork()
1 * stop()
}Sometimes an IDE has trouble to determine the type of the target, in that case you can help out by manually specifying the
target type via with(target, type, closure).
Using verifyAll to assert multiple expectations together
Normal expectations fail the test on the first failed assertions. Sometimes it is helpful to collect these failures before failing the test to have more information, this behavior is also known as soft assertions.
The verifyAll method can be used like with,
def "offered PC matches preferred configuration"() {
when:
def pc = shop.buyPc()
then:
verifyAll(pc) {
vendor == "Sunny"
clockRate >= 2333
ram >= 406
os == "Linux"
}
}or it can be used without a target.
expect:
verifyAll {
2 == 2
4 == 4
}Like with you can also optionally define a type hint for the IDE.
Specifications as Documentation
Well-written specifications are a valuable source of information. Especially for higher-level specifications targeting a wider audience than just developers (architects, domain experts, customers, etc.), it makes sense to provide more information in natural language than just the names of specifications and features. Therefore, Spock provides a way to attach textual descriptions to blocks:
given: "open a database connection"
// code goes hereUse the and: label to describe logically different parts of a block:
given: "open a database connection"
// code goes here
and: "seed the customer table"
// code goes here
and: "seed the product table"
// code goes hereAn and: label followed by a description can be inserted at any (top-level) position of a feature method, without
altering the method’s semantics.
In Behavior Driven Development, customer-facing features (called stories) are described in a given-when-then format.
Spock directly supports this style of specification with the given: label:
given: "an empty bank account"
// ...
when: "the account is credited \$10"
// ...
then: "the account's balance is \$10"
// ...Block descriptions are not only present in source code, but are also available to the Spock runtime. Planned usages of block descriptions are enhanced diagnostic messages, and textual reports that are equally understood by all stakeholders.
Extensions
As we have seen, Spock offers lots of functionality for writing specifications. However, there always comes a time when something else is needed. Therefore, Spock provides an interception-based extension mechanism. Extensions are activated by annotations called directives. Currently, Spock ships with the following directives:
@Timeout
|
Sets a timeout for execution of a feature or fixture method. |
@Ignore
|
Ignores any feature method carrying this annotation. |
@IgnoreRest
|
Any feature method carrying this annotation will be executed, all others will be ignored. Useful for quickly running just a single method. |
@FailsWith
|
Expects a feature method to complete abruptly. |
Go to the Extensions chapter to learn how to implement your own directives and extensions.
Comparison to JUnit
Although Spock uses a different terminology, many of its concepts and features are inspired by JUnit. Here is a rough comparison:
| Spock | JUnit |
|---|---|
Specification |
Test class |
|
|
|
|
|
|
|
|
Feature |
Test |
Feature method |
Test method |
Data-driven feature |
Theory |
Condition |
Assertion |
Exception condition |
|
Interaction |
Mock expectation (e.g. in Mockito) |
Data Driven Testing
Oftentimes, it is useful to exercise the same test code multiple times, with varying inputs and expected results. Spock’s data driven testing support makes this a first class feature.
Introduction
Suppose we want to specify the behavior of the Math.max method:
class MathSpec extends Specification {
def "maximum of two numbers"() {
expect:
// exercise math method for a few different inputs
Math.max(1, 3) == 3
Math.max(7, 4) == 7
Math.max(0, 0) == 0
}
}Although this approach is fine in simple cases like this one, it has some potential drawbacks:
-
Code and data are mixed and cannot easily be changed independently
-
Data cannot easily be auto-generated or fetched from external sources
-
In order to exercise the same code multiple times, it either has to be duplicated or extracted into a separate method
-
In case of a failure, it may not be immediately clear which inputs caused the failure
-
Exercising the same code multiple times does not benefit from the same isolation as executing separate methods does
Spock’s data-driven testing support tries to address these concerns. To get started, let’s refactor above code into a data-driven feature method. First, we introduce three method parameters (called data variables) that replace the hard-coded integer values:
class MathSpec extends Specification {
def "maximum of two numbers"(int a, int b, int c) {
expect:
Math.max(a, b) == c
...
}
}We have finished the test logic, but still need to supply the data values to be used. This is done in a where: block,
which always comes at the end of the method. In the simplest (and most common) case, the where: block holds a data table.
Data Tables
Data tables are a convenient way to exercise a feature method with a fixed set of data values:
class MathSpec extends Specification {
def "maximum of two numbers"(int a, int b, int c) {
expect:
Math.max(a, b) == c
where:
a | b | c
1 | 3 | 3
7 | 4 | 7
0 | 0 | 0
}
}The first line of the table, called the table header, declares the data variables. The subsequent lines, called table rows, hold the corresponding values. For each row, the feature method will get executed once; we call this an iteration of the method. If an iteration fails, the remaining iterations will nevertheless be executed. All failures will be reported.
Data tables must have at least two columns. A single-column table can be written as:
where:
a | _
1 | _
7 | _
0 | _A sequence of two or more underscores can be used to split one wide data table into multiple narrower ones.
Without this separator and without any other data variable assignment in between there
is no way to have multiple data tables in one where block, the second table would just
be further iterations of the first table, including the seemingly header row:
where:
a | _
1 | _
7 | _
0 | _
__
b | c
1 | 2
3 | 4
5 | 6This is semantically exactly the same, just as one wider combined data table:
where:
a | b | c
1 | 1 | 2
7 | 3 | 4
0 | 5 | 6The sequence of two or more underscores can be used anywhere in the where block.
It will be ignored everywhere, except for in between two data tables, where it is
used to separate the two data tables. This means that the separator can also be used
as styling element in different ways. It can be used as separator line like shown in
the last example or it can for example be used visually as top border of tables
additionally to its effect of separating them:
where:
_____
a | _
1 | _
7 | _
0 | _
_____
b | c
1 | 2
3 | 4
5 | 6Isolated Execution of Iterations
Iterations are isolated from each other in the same way as separate feature methods. Each iteration gets its own instance
of the specification class, and the setup and cleanup methods will be called before and after each iteration,
respectively.
Sharing of Objects between Iterations
In order to share an object between iterations, it has to be kept in a @Shared or static field.
|
Note
|
Only @Shared and static variables can be accessed from within a where: block.
|
Note that such objects will also be shared with other methods. There is currently no good way to share an object just between iterations of the same method. If you consider this a problem, consider putting each method into a separate spec, all of which can be kept in the same file. This achieves better isolation at the cost of some boilerplate code.
Syntactic Variations
The previous code can be tweaked in a few ways.
First, since the where: block already declares all data variables, the method parameters can be
omitted.[1]
You can also omit some parameters and specify others, for example to have them typed. The order also is not important, data variables are matched by name to the specified method parameters.
Second, inputs and expected outputs can be separated with a double pipe symbol (||) to visually set them apart.
With this, the code becomes:
class MathSpec extends Specification {
def "maximum of two numbers"() {
expect:
Math.max(a, b) == c
where:
a | b || c
1 | 3 || 3
7 | 4 || 7
0 | 0 || 0
}
}Alternatively to using single or double pipes you can also use any amount of semicolons to separate data columns from each other:
class MathSpec extends Specification {
def "maximum of two numbers"() {
expect:
Math.max(a, b) == c
where:
a ; b ;; c
1 ; 3 ;; 3
7 ; 4 ;; 7
0 ; 0 ;; 0
}
}Pipes and semicolons as data column separator can not be mixed within one table. If the column separator changes, this starts a new stand-alone data table:
class MathSpec extends Specification {
def "maximum of two numbers"() {
expect:
Math.max(a, b) == c
Math.max(d, e) == f
where:
a | b || c
1 | 3 || 3
7 | 4 || 7
0 | 0 || 0
d ; e ;; f
1 ; 3 ;; 3
7 ; 4 ;; 7
0 ; 0 ;; 0
}
}Reporting of Failures
Let’s assume that our implementation of the max method has a flaw, and one of the iterations fails:
maximum of two numbers [a: 1, b: 3, c: 3, #0] PASSED maximum of two numbers [a: 7, b: 4, c: 7, #1] FAILED Condition not satisfied: Math.max(a, b) == c | | | | | | | | 7 4 | 7 | 42 false class java.lang.Math maximum of two numbers [a: 0, b: 0, c: 0, #2] PASSED
The obvious question is: Which iteration failed, and what are its data values? In our example, it isn’t hard to figure out that it’s the second iteration (with index 1) that failed even from the rich condition rendering. At other times this can be more difficult or even impossible.[2] In any case, Spock makes it loud and clear which iteration failed, rather than just reporting the failure. Iterations of a feature method are by default unrolled with a rich naming pattern. This pattern can also be configured as documented at Unrolled Iteration Names or the unrolling can be disabled like described in the following section.
Method Uprolling and Unrolling
A method annotated with @Rollup will have its iterations not reported independently but only aggregated within the
feature. This can for example be used if you produce many test cases from calculations or if you use external data
like the contents of a database as test data and do not want the test count to vary:
@Rollup
def "maximum of two numbers"() {
...Note that up- and unrolling has no effect on how the method gets executed; it is only an alternation in reporting. Depending on the execution environment, the output will look something like:
maximum of two numbers FAILED Condition not satisfied: Math.max(a, b) == c | | | | | | | | 7 4 | 7 | 42 false class java.lang.Math
The @Rollup annotation can also be placed on a spec.
This has the same effect as placing it on each data-driven feature method of the spec that does not have an
@Unroll annotation.
Alternatively the configuration file setting unrollByDefault
in the unroll section can be set to false to roll up all features automatically unless
they are annotated with @Unroll or are contained in an @Unrolled spec and thus reinstate the pre Spock 2.0
behavior where this was the default.
unroll {
unrollByDefault false
}It is illegal to annotate a spec or a feature with both the @Unroll and the @Rollup annotation and if detected
this will cause an exception to be thrown.
To summarize:
A feature will be uprolled
-
if the method is annotated with
@Rollup -
if the method is not annotated with
@Unrolland the spec is annotated with@Rollup -
if neither the method nor the spec is annotated with
@Unrolland the configuration optionunroll { unrollByDefault }is set tofalse
A feature will be unrolled
-
if the method is annotated with
@Unroll -
if the method is not annotated with
@Rollupand the spec is annotated with@Unroll -
if neither the method nor the spec is annotated with
@Rollupand the configuration optionunroll { unrollByDefault }is set to its default valuetrue
Data Pipes
Data tables aren’t the only way to supply values to data variables. In fact, a data table is just syntactic sugar for one or more data pipes:
...
where:
a << [1, 7, 0]
b << [3, 4, 0]
c << [3, 7, 0]A data pipe, indicated by the left-shift (<<) operator, connects a data variable to a data provider. The data
provider holds all values for the variable, one per iteration. Any object that Groovy knows how to iterate over can be
used as a data provider. This includes objects of type Collection, String, Iterable, and objects implementing the
Iterable contract. Data providers don’t necessarily have to be the data (as in the case of a Collection);
they can fetch data from external sources like text files, databases and spreadsheets, or generate data randomly.
Data providers are queried for their next value only when needed (before the next iteration).
Multi-Variable Data Pipes
If a data provider returns multiple values per iteration (as an object that Groovy knows how to iterate over), it can be connected to multiple data variables simultaneously. The syntax is somewhat similar to Groovy multi-assignment but uses brackets instead of parentheses on the left-hand side:
@Shared sql = Sql.newInstance("jdbc:h2:mem:", "org.h2.Driver")
def "maximum of two numbers"() {
expect:
Math.max(a, b) == c
where:
[a, b, c] << sql.rows("select a, b, c from maxdata")
}Data values that aren’t of interest can be ignored with an underscore (_):
...
where:
[a, b, _, c] << sql.rows("select * from maxdata")The multi-assignments can even be nested. The following example will generate these iterations:
| a | b | c |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
...
where:
[a, [b, _, c]] << [
['a1', 'a2'].permutations(),
[
['b1', 'd1', 'c1'],
['b2', 'd2', 'c2']
]
].combinations()Named deconstruction of data pipes
Since Spock 2.2, multi variable data pipes can also be deconstructed from maps. This is useful when the data provider returns a map with named keys. Or, if you have long values that don’t fit well into a data-table, then using the maps makes it easier to read.
...
where:
[a, b, c] << [
[
a: 1,
b: 3,
c: 5
],
[
a: 2,
b: 4,
c: 6
]
]You can use named deconstruction with nested data pipes, but only on the innermost nesting level.
...
where:
[a, [b, c]] << [
[1, [b: 3, c: 5]],
[2, [c: 6, b: 4]]
]Data Variable Assignment
A data variable can be directly assigned a value:
...
where:
a = 3
b = Math.random() * 100
c = a > b ? a : bAssignments are re-evaluated for every iteration. As already shown above, the right-hand side of an assignment may refer to other data variables:
...
where:
row << sql.rows("select * from maxdata")
// pick apart columns
a = row.a
b = row.b
c = row.cAccessing Other Data Variables
There are only two possibilities to access one data variable from the calculation of another data variable.
The first possibility are derived data variables like shown in the last section. Every data variable that is defined by a direct assignment can access all previously defined data variables, including the ones defined through data tables or data pipes:
...
where:
a = 3
b = Math.random() * 100
c = a > b ? a : bThe second possibility is to access previous columns within data tables:
...
where:
a | b
3 | a + 1
7 | a + 2
0 | a + 3This also includes columns in previous data tables in the same where block:
...
where:
a | b
3 | a + 1
7 | a + 2
0 | a + 3
and:
c = 1
and:
d | e
a * 2 | b * 2
a * 3 | b * 3
a * 4 | b * 4Multi-Variable Assignment
Like with data pipes, you can also assign to multiple variables in one expression, if you have some object Groovy can iterate over. Unlike with data pipes, the syntax here is identical to standard Groovy multi-assignment syntax:
@Shared sql = Sql.newInstance("jdbc:h2:mem:", "org.h2.Driver")
def "maximum of two numbers multi-assignment"() {
expect:
Math.max(a, b) == c
where:
row << sql.rows("select a, b, c from maxdata")
(a, b, c) = row
}Data values that aren’t of interest can be ignored with an underscore (_):
...
where:
row << sql.rows("select * from maxdata")
(a, b, _, c) = rowCombining Data Tables, Data Pipes, and Variable Assignments
Data tables, data pipes, and variable assignments can be combined as needed:
...
where:
a | b
1 | a + 1
7 | a + 2
0 | a + 3
c << [3, 4, 0]
d = a > c ? a : cType Coercion for Data Variable Values
Data variable values are coerced to the declared parameter type using
type coercion. Due to that custom type conversions can be
provided as extension module or with the help of
the @Use extension on the specification (as it has no effect to the where: block if
applied to a feature).
def "type coercion for data variable values"(Integer i) {
expect:
i instanceof Integer
i == 10
where:
i = "10"
}@Use(CoerceBazToBar)
class Foo extends Specification {
def foo(Bar bar) {
expect:
bar == Bar.FOO
where:
bar = Baz.FOO
}
}
enum Bar { FOO, BAR }
enum Baz { FOO, BAR }
class CoerceBazToBar {
static Bar asType(Baz self, Class<Bar> clazz) {
return Bar.valueOf(self.name())
}
}Number of Iterations
The number of iterations depends on how much data is available. Successive executions of the same method can
yield different numbers of iterations. If a data provider runs out of values sooner than its peers, an exception will occur.
Variable assignments don’t affect the number of iterations. A where: block that only contains assignments yields
exactly one iteration.
Closing of Data Providers
After all iterations have completed, the zero-argument close method is called on all data providers that have
such a method.
Unrolled Iteration Names
By default, the names of unrolled iterations are the name of the feature, plus the data variables and the iteration index. This will always produce unique names and should enable you to identify easily the failing data variable combination.
The example at Reporting of Failures for example shows with maximum of two numbers [a: 7, b: 4, c: 7, #1],
that the second iteration (#1) where the data variables have the values 7, 4 and 7 failed.
With a bit of effort, we can do even better:
def "maximum of #a and #b is #c"() {
...This method name uses placeholders, denoted by a leading hash sign (#), to refer to data variables a, b, and c.
In the output, the placeholders will be replaced with concrete values:
maximum of 1 and 3 is 3 PASSED maximum of 7 and 4 is 7 FAILED Math.max(a, b) == c | | | | | | | | 7 4 | 7 | 42 false class java.lang.Math maximum of 0 and 0 is 0 PASSED
Now we can tell at a glance that the max method failed for inputs 7 and 4.
An unrolled method name is similar to a Groovy GString, except for the following differences:
-
Expressions are denoted with
#instead of$, and there is no equivalent for the${…}syntax. -
Expressions only support property access and zero-arg method calls.
Given a class Person with properties name and age, and a data variable person of type Person, the
following are valid method names:
def "#person is #person.age years old"() { // property access
def "#person.name.toUpperCase()"() { // zero-arg method callNon-string values (like #person above) are converted to Strings according to Groovy semantics.
The following are invalid method names:
def "#person.name.split(' ')[1]" { // cannot have method arguments
def "#person.age / 2" { // cannot use operatorsIf necessary, additional data variables can be introduced to hold more complex expressions:
def "#lastName"() {
...
where:
person << [new Person(age: 14, name: 'Phil Cole')]
lastName = person.name.split(' ')[1]
}Additionally, to the data variables the tokens #featureName and #iterationIndex are supported.
The former does not make much sense inside an actual feature name, but there are two other places
where an unroll-pattern can be defined, where it is more useful.
def "#person is #person.age years old [#iterationIndex]"() {will be reported as
╷
└─ Spock ✔
└─ PersonSpec ✔
└─ #person.name is #person.age years old [#iterationIndex] ✔
├─ Fred is 38 years old [0] ✔
├─ Wilma is 36 years old [1] ✔
└─ Pebbles is 5 years old [2] ✔
Alternatively, to specifying the unroll-pattern as method name, it can be given as parameter
to the @Unroll annotation which takes precedence over the method name:
@Unroll("#featureName[#iterationIndex] (#person.name is #person.age years old)")
def "person age should be calculated properly"() {
// ...will be reported as
╷
└─ Spock ✔
└─ PersonSpec ✔
└─ person age should be calculated properly ✔
├─ person age should be calculated properly[0] (Fred is 38 years old) ✔
├─ person age should be calculated properly[1] (Wilma is 36 years old) ✔
└─ person age should be calculated properly[2] (Pebbles is 5 years old) ✔
The advantage is, that you can have a descriptive method name for the whole feature, while having a separate template for each iteration. Furthermore, the feature method name is not filled with placeholders and thus better readable.
If neither a parameter to the annotation is given, nor the method name contains a #,
the configuration file setting defaultPattern
in the unroll section is inspected. If it is set to a non-null
string, this value is used as unroll-pattern. This could for example be set to
-
#featureNameto have all iterations reported with the same name, or -
#featureName[#iterationIndex]to have a simply indexed iteration name, or -
#iterationNameif you make sure that in each data-driven feature you also set a data variable callediterationNamethat is then used for reporting
Special Tokens
This is the complete list of special tokens:
-
#featureNameis the name of the feature (mostly useful for thedefaultPatternsetting) -
#iterationIndexis the current iteration index -
#dataVariableslists all data variables for this iteration, e.g.x: 1, y: 2, z: 3 -
#dataVariablesWithIndexthe same as#dataVariablesbut with an index at the end, e.g.x: 1, y: 2, z: 3, #0
Configuration
unroll {
defaultPattern '#featureName[#iterationIndex]'
}If none of the three described ways is used to set a custom unroll-pattern, by default
the feature name is used, suffixed with all data variable names and their values and
finally the iteration index, so the result will be for example
my feature [x: 1, y: 2, z: 3, #0].
If there is an error in an unroll expression, for example typo in variable name, exception during evaluation of a property or method in the expression and so on, the test will fail. This is not true for the automatic fall back rendering of the data variables if there is no unroll-pattern set in any way, this will never fail the test, no matter what happens.
The failing of test with errors in the unroll expression can be disabled by setting the
configuration file setting validateExpressions
in the unroll section to false. If this is done and an error happens, the erroneous expression
#foo.bar will be substituted by #Error:foo.bar.
unroll {
validateExpressions false
}Some reporting frameworks, or IDEs support proper tree based reporting. For these cases it might be desirable to omit the feature name from the iteration reporting.
unroll {
includeFeatureNameForIterations false
}With includeFeatureNameForIterations true
╷
└─ Spock ✔
└─ ASpec ✔
└─ really long and informative test name that doesn't have to be repeated ✔
├─ really long and informative test name that doesn't have to be repeated [x: 1, y: a, #0] ✔
├─ really long and informative test name that doesn't have to be repeated [x: 2, y: b, #1] ✔
└─ really long and informative test name that doesn't have to be repeated [x: 3, y: c, #2] ✔
includeFeatureNameForIterations false╷
└─ Spock ✔
└─ ASpec ✔
└─ really long and informative test name that doesn't have to be repeated ✔
├─ x: 1, y: a, #0 ✔
├─ x: 2, y: b, #1 ✔
└─ x: 3, y: c, #2 ✔
|
Note
|
The same can be achieved for individual features by using @Unroll('#dataVariablesWithIndex').
|
Interaction Based Testing
Interaction-based testing is a design and testing technique that emerged in the Extreme Programming (XP) community in the early 2000’s. Focusing on the behavior of objects rather than their state, it explores how the object(s) under specification interact, by way of method calls, with their collaborators.
For example, suppose we have a Publisher that sends messages to its `Subscriber`s:
class Publisher {
List<Subscriber> subscribers = []
int messageCount = 0
void send(String message){
subscribers*.receive(message)
messageCount++
}
}
interface Subscriber {
void receive(String message)
}
class PublisherSpec extends Specification {
Publisher publisher = new Publisher()
}How are we going to test Publisher? With state-based testing, we can verify that the publisher keeps track of its
subscribers. The more interesting question, though, is whether a message sent by the publisher
is received by the subscribers. To answer this question, we need a special implementation of
Subscriber that listens in on the conversation between the publisher and its subscribers. Such an
implementation is called a mock object.
While we could certainly create a mock implementation of Subscriber by hand, writing and maintaining this code
can get unpleasant as the number of methods and complexity of interactions increases. This is where mocking frameworks
come in: They provide a way to describe the expected interactions between an object under specification and its
collaborators, and can generate mock implementations of collaborators that verify these expectations.
The Java world has no shortage of popular and mature mocking frameworks: JMock, EasyMock, Mockito, to name just a few. Although each of these tools can be used together with Spock, we decided to roll our own mocking framework, tightly integrated with Spock’s specification language. This decision was driven by the desire to leverage all of Groovy’s capabilities to make interaction-based tests easier to write, more readable, and ultimately more fun. We hope that by the end of this chapter, you will agree that we have achieved these goals.
Except where indicated, all features of Spock’s mocking framework work both for testing Java and Groovy code.
Creating Mock Objects
Mock objects are created with the MockingApi.Mock() method.[3]
Let’s create two mock subscribers:
def subscriber = Mock(Subscriber)
def subscriber2 = Mock(Subscriber)Alternatively, the following Java-like syntax is supported, which may give better IDE support:
Subscriber subscriber = Mock()
Subscriber subscriber2 = Mock()Here, the mock’s type is inferred from the variable type on the left-hand side of the assignment.
|
Note
|
If the mock’s type is given on the left-hand side of the assignment, it’s permissible (though not required) to omit it on the right-hand side. |
Mock objects literally implement (or, in the case of a class, extend) the type they stand in for. In other
words, in our example subscriber is-a Subscriber. Hence it can be passed to statically typed (Java)
code that expects this type.
Default Behavior of Mock Objects
Initially, mock objects have no behavior. Calling methods on them is allowed but has no effect other than returning
the default value for the method’s return type (false, 0, or null). An exception are the Object.equals,
Object.hashCode, and Object.toString methods, which have the following default behavior: A mock object is only
equal to itself, has a unique hash code, and a string representation that includes the name of the type it represents.
This default behavior is overridable by stubbing the methods, which we will learn about in the Stubbing section.
Injecting Mock Objects into Code Under Specification
After creating the publisher and its subscribers, we need to make the latter known to the former:
class PublisherSpec extends Specification {
Publisher publisher = new Publisher()
Subscriber subscriber = Mock()
Subscriber subscriber2 = Mock()
def setup() {
publisher.subscribers << subscriber // << is a Groovy shorthand for List.add()
publisher.subscribers << subscriber2
}We are now ready to describe the expected interactions between the two parties.
Mocking
Mocking is the act of describing (mandatory) interactions between the object under specification and its collaborators. Here is an example:
def "should send messages to all subscribers"() {
when:
publisher.send("hello")
then:
1 * subscriber.receive("hello")
1 * subscriber2.receive("hello")
}Read out aloud: "When the publisher sends a 'hello' message, then both subscribers should receive that message exactly once."
When this feature method gets run, all invocations on mock objects that occur while executing the
when block will be matched against the interactions described in the then: block. If one of the interactions isn’t
satisfied, a (subclass of) InteractionNotSatisfiedError will be thrown. This verification happens automatically
and does not require any additional code.
Interactions
Let’s take a closer look at the then: block. It contains two interactions, each of which has four distinct
parts: a cardinality, a target constraint, a method constraint, and an argument constraint:
1 * subscriber.receive("hello")
| | | |
| | | argument constraint
| | method constraint
| target constraint
cardinality
Cardinality
The cardinality of an interaction describes how often a method call is expected. It can either be a fixed number or a range:
1 * subscriber.receive("hello") // exactly one call
0 * subscriber.receive("hello") // zero calls
(1..3) * subscriber.receive("hello") // between one and three calls (inclusive)
(1.._) * subscriber.receive("hello") // at least one call
(_..3) * subscriber.receive("hello") // at most three calls
_ * subscriber.receive("hello") // any number of calls, including zero
// (rarely needed; see 'Strict Mocking')Target Constraint
The target constraint of an interaction describes which mock object is expected to receive the method call:
1 * subscriber.receive("hello") // a call to 'subscriber'
1 * _.receive("hello") // a call to any mock objectMethod Constraint
The method constraint of an interaction describes which method is expected to be called:
1 * subscriber.receive("hello") // a method named 'receive'
1 * subscriber./r.*e/("hello") // a method whose name matches the given regular expression
// (here: method name starts with 'r' and ends in 'e')When expecting a call to a getter method, Groovy property syntax can be used instead of method syntax:
1 * subscriber.status // same as: 1 * subscriber.getStatus()When expecting a call to a setter method, only method syntax can be used:
1 * subscriber.setStatus("ok") // NOT: 1 * subscriber.status = "ok"Argument Constraints
The argument constraints of an interaction describe which method arguments are expected:
1 * subscriber.receive("hello") // an argument that is equal to the String "hello"
1 * subscriber.receive(!"hello") // an argument that is unequal to the String "hello"
1 * subscriber.receive() // the empty argument list (would never match in our example)
1 * subscriber.receive(_) // any single argument (including null)
1 * subscriber.receive(*_) // any argument list (including the empty argument list)
1 * subscriber.receive(!null) // any non-null argument
1 * subscriber.receive(_ as String) // any non-null argument that is-a String
1 * subscriber.receive(endsWith("lo")) // an argument matching the given Hamcrest matcher
// a String argument ending with "lo" in this case
1 * subscriber.receive({ it.size() > 3 && it.contains('a') })
// an argument that satisfies the given predicate, meaning that
// code argument constraints need to return true of false
// depending on whether they match or not
// (here: message length is greater than 3 and contains the character a)Argument constraints work as expected for methods with multiple arguments:
1 * process.invoke("ls", "-a", _, !null, { ["abcdefghiklmnopqrstuwx1"].contains(it) })When dealing with vararg methods, vararg syntax can also be used in the corresponding interactions:
interface VarArgSubscriber {
void receive(String... messages)
}
...
subscriber.receive("hello", "goodbye")Equality Constraint
The equality constraint uses groovy equality to check the argument, i.e, argument == constraint. You can use
-
any literal
1 * check('string')/1 * check(1)/1 * check(null), -
a variable
1 * check(var), -
a list or map literal
1 * check([1])/1 * check([foo: 'bar']), -
an object
1 * check(new Person('sam')), -
or the result of a method call
1 * check(person())
as an equality constraint.
Hamcrest Constraint
A variation of the equality constraint, if the constraint object is a Hamcrest matcher, then it will use that matcher to check the argument.
Wildcard Constraint
The wildcard constraint will match any argument null or otherwise. It is the , i.e. 1 * subscriber.receive().
There is also the spread wildcard constraint *_ which matches any number of arguments 1 * subscriber.receive(*_) including none.
Code Constraint
The code constraint is the most versatile of all. It is a groovy closure that gets the argument as its parameter.
The closure is treated as an condition block, so it behaves like a then block, i.e., every line is treated as an implicit assertion.
It can emulate all but the spread wildcard constraint, however it is suggested to use the simpler constraints where possible.
You can do multiple assertions, call methods for assertions, or use with/verifyAll.
1 * list.add({
verifyAll(it, Person) {
firstname == 'William'
lastname == 'Kirk'
age == 45
}
})Negating Constraint
The negating constraint ! is a compound constraint, i.e. it needs to be combined with another constraint to work.
It inverts the result of the nested constraint, e.g, 1 * subscriber.receive(!null) is the combination of
an equality constraint checking for null and then the negating constraint inverting the result, turning it into not null.
Although it can be combined with any other constraint it does not always make sense, e.g., 1 * subscriber.receive(!_) will match nothing.
Also keep in mind that the diagnostics for a non matching negating constraint will just be that the inner
constraint did match, without any more information.
Type Constraint
The type constraint checks for the type/class of the argument, like the negating constraint it is also a compound constraint.
It usually written as _ as Type, which is a combination of the wildcard constraint and the type constraint.
You can combined it with other constraints as well, 1 * subscriber.receive({ it.contains('foo')} as String) will assert that it is
a String before executing the code constraint to check if it contains foo.
Matching Any Method Call
Sometimes it can be useful to match "anything", in some sense of the word:
1 * subscriber._(*_) // any method on subscriber, with any argument list
1 * subscriber._ // shortcut for and preferred over the above
1 * _._ // any method call on any mock object
1 * _ // shortcut for and preferred over the above|
Note
|
Although (_.._) * _._(*_) >> _ is a valid interaction declaration,
it is neither good style nor particularly useful.
|
Strict Mocking
Now, when would matching any method call be useful? A good example is strict mocking, a style of mocking where no interactions other than those explicitly declared are allowed:
when:
publisher.publish("hello")
then:
1 * subscriber.receive("hello") // demand one 'receive' call on 'subscriber'
_ * auditing._ // allow any interaction with 'auditing'
0 * _ // don't allow any other interaction0 * only makes sense as the last interaction of a then: block or method. Note the
use of _ * (any number of calls), which allows any interaction with the auditing component.
|
Note
|
_ * is only meaningful in the context of strict mocking. In particular, it is never necessary
when Stubbing an invocation. For example, _ * auditing.record() >> "ok"
can (and should!) be simplified to auditing.record() >> "ok".
|
Where to Declare Interactions
So far, we declared all our interactions in a then: block. This often results in a spec that reads naturally.
However, it is also permissible to put interactions anywhere before the when: block that is supposed to satisfy
them. In particular, this means that interactions can be declared in a setup method. Interactions can also be
declared in any "helper" instance method of the same specification class.
When an invocation on a mock object occurs, it is matched against interactions in the interactions' declared order.
If an invocation matches multiple interactions, the earliest declared interaction that hasn’t reached its upper
invocation limit will win. There is one exception to this rule: Interactions declared in a then: block are
matched against before any other interactions. This allows to override interactions declared in, say, a setup
method with interactions declared in a then: block.
Declaring Interactions at Mock Creation Time
If a mock has a set of "base" interactions that don’t vary, they can be declared right at mock creation time:
Subscriber subscriber = Mock {
1 * receive("hello")
1 * receive("goodbye")
}This feature is particularly attractive for Stubbing and with dedicated Stubs. Note that the interactions don’t (and cannot [4]) have a target constraint; it’s clear from the context which mock object they belong to.
Interactions can also be declared when initializing an instance field with a mock:
class MySpec extends Specification {
Subscriber subscriber = Mock {
1 * receive("hello")
1 * receive("goodbye")
}
}Grouping Interactions with Same Target
Interactions sharing the same target can be grouped in a Specification.with block. Similar to
Declaring Interactions at Mock Creation Time, this makes it unnecessary
to repeat the target constraint:
with(subscriber) {
1 * receive("hello")
1 * receive("goodbye")
}A with block can also be used for grouping conditions with the same target.
Mixing Interactions and Conditions
A then: block may contain both interactions and conditions. Although not strictly required, it is customary
to declare interactions before conditions:
when:
publisher.send("hello")
then:
1 * subscriber.receive("hello")
publisher.messageCount == 1Read out aloud: "When the publisher sends a 'hello' message, then the subscriber should receive the message exactly once, and the publisher’s message count should be one."
Explicit Interaction Blocks
Internally, Spock must have full information about expected interactions before they take place.
So how is it possible for interactions to be declared in a then: block?
The answer is that under the hood, Spock moves interactions declared in a then: block to immediately
before the preceding when: block. In most cases this works out just fine, but sometimes it can lead to problems:
when:
publisher.send("hello")
then:
def message = "hello"
1 * subscriber.receive(message)Here we have introduced a variable for the expected argument. (Likewise, we could have introduced a variable
for the cardinality.) However, Spock isn’t smart enough (huh?) to tell that the interaction is intrinsically
linked to the variable declaration. Hence it will just move the interaction, which will cause a
MissingPropertyException at runtime.
One way to solve this problem is to move (at least) the variable declaration to before the when:
block. (Fans of Data Driven Testing might move the variable into a where: block.)
In our example, this would have the added benefit that we could use the same variable for sending the message.
Another solution is to be explicit about the fact that variable declaration and interaction belong together:
when:
publisher.send("hello")
then:
interaction {
def message = "hello"
1 * subscriber.receive(message)
}Since an MockingApi.interaction block is always moved in its entirety, the code now works as intended.
Scope of Interactions
Interactions declared in a then: block are scoped to the preceding when: block:
when:
publisher.send("message1")
then:
1 * subscriber.receive("message1")
when:
publisher.send("message2")
then:
1 * subscriber.receive("message2")This makes sure that subscriber receives "message1" during execution of the first when: block,
and "message2" during execution of the second when: block.
Interactions declared outside a then: block are active from their declaration until the end of the
containing feature method.
Interactions are always scoped to a particular feature method. Hence they cannot be declared in a static method,
setupSpec method, or cleanupSpec method. Likewise, mock objects should not be stored in static or @Shared
fields.
Verification of Interactions
There are two main ways in which a mock-based test can fail: An interaction can match more invocations than
allowed, or it can match fewer invocations than required. The former case is detected right when the invocation
happens, and causes a TooManyInvocationsError:
Too many invocations for: 2 * subscriber.receive(_) (3 invocations)
To make it easier to diagnose why too many invocations matched, Spock will show all invocations matching the interaction in question:
Matching invocations (ordered by last occurrence):
2 * subscriber.receive("hello") <-- this triggered the error
1 * subscriber.receive("goodbye")
According to this output, one of the receive("hello") calls triggered the TooManyInvocationsError.
Note that because indistinguishable calls like the two invocations of subscriber.receive("hello") are aggregated
into a single line of output, the first receive("hello") may well have occurred before the receive("goodbye").
The second case (fewer invocations than required) can only be detected once execution of the when block has completed.
(Until then, further invocations may still occur.) It causes a TooFewInvocationsError:
Too few invocations for:
1 * subscriber.receive("hello") (0 invocations)
Note that it doesn’t matter whether the method was not called at all, the same method was called with different arguments,
the same method was called on a different mock object, or a different method was called "instead" of this one;
in either case, a TooFewInvocationsError error will occur.
To make it easier to diagnose what happened "instead" of a missing invocation, Spock will show all invocations that didn’t match any interaction, ordered by their similarity with the interaction in question. In particular, invocations that match everything but the interaction’s arguments will be shown first:
Unmatched invocations (ordered by similarity):
1 * subscriber.receive("goodbye")
1 * subscriber2.receive("hello")Invocation Order
Often, the exact method invocation order isn’t relevant and may change over time. To avoid over-specification, Spock defaults to allowing any invocation order, provided that the specified interactions are eventually satisfied:
then:
2 * subscriber.receive("hello")
1 * subscriber.receive("goodbye")Here, any of the invocation sequences "hello" "hello" "goodbye", "hello" "goodbye" "hello", and
"goodbye" "hello" "hello" will satisfy the specified interactions.
In those cases where invocation order matters, you can impose an order by splitting up interactions into
multiple then: blocks:
then:
2 * subscriber.receive("hello")
then:
1 * subscriber.receive("goodbye")Now Spock will verify that both "hello"'s are received before the "goodbye".
In other words, invocation order is enforced between but not within then: blocks.
|
Note
|
Splitting up a then: block with and: does not impose any ordering, as and:
is only meant for documentation purposes and doesn’t carry any semantics.
|
Mocking Classes
Besides interfaces, Spock also supports mocking of classes. Mocking classes works
just like mocking interfaces; the only additional requirement is to put byte-buddy 1.9+ or
cglib-nodep 3.2.0+ on the class path.
When using for example
-
normal
Mocks orStubs or -
Spys that are configured withuseObjenesis: trueor -
Spys that spy on a concrete instance likeSpy(myInstance)
it is also necessary to put objenesis 3.0+ on the class path, except for classes with accessible
no-arg constructor or configured constructorArgs unless the constructor call should not be done,
for example to avoid unwanted side effects.
If either of these libraries is missing from the class path, Spock will gently let you know.
Stubbing
Stubbing is the act of making collaborators respond to method calls in a certain way. When stubbing a method, you don’t care if and how many times the method is going to be called; you just want it to return some value, or perform some side effect, whenever it gets called.
For the sake of the following examples, let’s modify the Subscriber's receive method
to return a status code that tells if the subscriber was able to process a message:
interface Subscriber {
String receive(String message)
}Now, let’s make the receive method return "ok" on every invocation:
subscriber.receive(_) >> "ok"Read out aloud: "Whenever the subscriber receives a message, make it respond with 'ok'."
Compared to a mocked interaction, a stubbed interaction has no cardinality on the left end, but adds a response generator on the right end:
subscriber.receive(_) >> "ok" | | | | | | | response generator | | argument constraint | method constraint target constraint
A stubbed interaction can be declared in the usual places: either inside a then: block, or anywhere before a
when: block. (See Where to Declare Interactions for the details.) If a mock object is only used for stubbing,
it’s common to declare interactions at mock creation time or in a
given: block.
Returning Fixed Values
We have already seen the use of the right-shift (>>) operator to return a fixed value:
subscriber.receive(_) >> "ok"To return different values for different invocations, use multiple interactions:
subscriber.receive("message1") >> "ok"
subscriber.receive("message2") >> "fail"This will return "ok" whenever "message1" is received, and "fail" whenever
"message2" is received. There is no limit as to which values can be returned, provided they are
compatible with the method’s declared return type.
Returning Sequences of Values
To return different values on successive invocations, use the triple-right-shift (>>>) operator:
subscriber.receive(_) >>> ["ok", "error", "error", "ok"]This will return "ok" for the first invocation, "error" for the second and third invocation,
and "ok" for all remaining invocations. The right-hand side must be a value that Groovy knows how to iterate over;
in this example, we’ve used a plain list.
Computing Return Values
To compute a return value based on the method’s argument, use the the right-shift (>>) operator together with a closure.
If the closure declares a single untyped parameter, it gets passed the method’s argument list:
subscriber.receive(_) >> { args -> args[0].size() > 3 ? "ok" : "fail" }Here "ok" gets returned if the message is more than three characters long, and "fail" otherwise.
In most cases it would be more convenient to have direct access to the method’s arguments. If the closure declares more than one parameter or a single typed parameter, method arguments will be mapped one-by-one to closure parameters:[5]
subscriber.receive(_) >> { String message -> message.size() > 3 ? "ok" : "fail" }This response generator behaves the same as the previous one, but is arguably more readable.
If you find yourself in need of more information about a method invocation than its arguments, have a look at
org.spockframework.mock.IMockInvocation. All methods declared in this interface are available inside the closure,
without a need to prefix them. (In Groovy terminology, the closure delegates to an instance of IMockInvocation.)
Performing Side Effects
Sometimes you may want to do more than just computing a return value. A typical example is throwing an exception. Again, closures come to the rescue:
subscriber.receive(_) >> { throw new InternalError("ouch") }Of course, the closure can contain more code, for example a println statement. It
will get executed every time an incoming invocation matches the interaction.
Chaining Method Responses
Method responses can be chained:
subscriber.receive(_) >>> ["ok", "fail", "ok"] >> { throw new InternalError() } >> "ok"This will return "ok", "fail", "ok" for the first three invocations, throw InternalError
for the fourth invocations, and return ok for any further invocation.
Returning a default response
If you don’t really care what you return, but you must return a non-null value, you can use _.
This will use the same logic to compute a response as Stub (see Stubs), so it is only really useful for Mock and Spy instances.
subscriber.receive(_) >> _You can of course use this with chaining as well. Here it might be useful for Stub instances as well.
subscriber.receive(_) >>> ["ok", "fail"] >> _ >> "ok"An application of this is to let a Mock behave like a Stub, but still be able to do assertions.
The default response will return the mock itself, if the return type of the method is assignable from the mock type (excluding object).
This is useful when dealing with fluent APIs, like builders, which are otherwise really painful to mock.
given:
ThingBuilder builder = Mock() {
_ >> _
}
when:
Thing thing = builder
.id("id-42")
.name("spock")
.weight(100)
.build()
then:
1 * builder.build() >> new Thing(id: 'id-1337')
thing.id == 'id-1337'The _ >> _ instructs the mock to return the default response for all interactions.
However, interactions defined in the then block will have precedence over the interactions defined in the given block,
this lets us override and assert the interaction we actually care about.
Combining Mocking and Stubbing
Mocking and stubbing go hand-in-hand:
1 * subscriber.receive("message1") >> "ok"
1 * subscriber.receive("message2") >> "fail"When mocking and stubbing the same method call, they have to happen in the same interaction. In particular, the following Mockito-style splitting of stubbing and mocking into two separate statements will not work:
given:
subscriber.receive("message1") >> "ok"
when:
publisher.send("message1")
then:
1 * subscriber.receive("message1")As explained in Where to Declare Interactions, the receive call will first get matched against
the interaction in the then: block. Since that interaction doesn’t specify a response, the default
value for the method’s return type (null in this case) will be returned. (This is just another
facet of Spock’s lenient approach to mocking.). Hence, the interaction in the given: block will never
get a chance to match.
|
Note
|
Mocking and stubbing of the same method call has to happen in the same interaction. |
Other Kinds of Mock Objects
So far, we have created mock objects with the MockingApi.Mock method. Aside from
this method, the MockingApi class provides a couple of other factory methods for creating
more specialized kinds of mock objects.
Stubs
A stub is created with the MockingApi.Stub factory method:
Subscriber subscriber = Stub()Whereas a mock can be used both for stubbing and mocking, a stub can only be used for stubbing. Limiting a collaborator to a stub communicates its role to the readers of the specification.
|
Note
|
If a stub invocation matches a mandatory interaction (like 1 * foo.bar()), an InvalidSpecException is thrown.
|
Like a mock, a stub allows unexpected invocations. However, the values returned by a stub in such cases are more ambitious:
-
For primitive types, the primitive type’s default value is returned.
-
For non-primitive numerical values (such as
BigDecimal), zero is returned. -
If the value is assignable from the stub instance, then the instance is returned (e.g. builder pattern)
-
For non-numerical values, an "empty" or "dummy" object is returned. This could mean an empty String, an empty collection, an object constructed from its default constructor, or another stub returning default values. See class
org.spockframework.mock.EmptyOrDummyResponsefor the details.
|
Note
|
If the response type of the method is a final class or if it requires a class-mocking library and cglib or ByteBuddy
are not available, then the "dummy" object creation will fail with a CannotCreateMockException.
|
A stub often has a fixed set of interactions, which makes declaring interactions at mock creation time particularly attractive:
Subscriber subscriber = Stub {
receive("message1") >> "ok"
receive("message2") >> "fail"
}Spies
(Think twice before using this feature. It might be better to change the design of the code under specification.)
A spy is created with the MockingApi.Spy factory method:
SubscriberImpl subscriber = Spy(constructorArgs: ["Fred"])A spy is always based on a real object. Hence you must provide a class type rather than an interface type, along with any constructor arguments for the type. If no constructor arguments are provided, the type’s no-arg constructor will be used.
If the given constructor arguments lead to an ambiguity, you can cast the constructor
arguments as usual using as or Java-style cast. If the testee for example has
one constructor with a String parameter and one with a Pattern parameter
and you want null as constructorArg:
SubscriberImpl subscriber = Spy(constructorArgs: [null as String])
SubscriberImpl subscriber2 = Spy(constructorArgs: [(Pattern) null])You may also create a spy from an instantiated object. This may be useful in cases where you do not have full control over the instantiation of types you are interested in spying. (For example when testing within a Dependency Injection framework such as Spring or Guice.)
Method calls on a spy are automatically delegated to the real object. Likewise, values returned from the real object’s methods are passed back to the caller via the spy.
After creating a spy, you can listen in on the conversation between the caller and the real object underlying the spy:
1 * subscriber.receive(_)Apart from making sure that receive gets called exactly once,
the conversation between the publisher and the SubscriberImpl instance underlying the spy remains unaltered.
When stubbing a method on a spy, the real method no longer gets called:
subscriber.receive(_) >> "ok"Instead of calling SubscriberImpl.receive, the receive method will now simply return "ok".
Sometimes, it is desirable to both execute some code and delegate to the real method:
subscriber.receive(_) >> { String message -> callRealMethod(); message.size() > 3 ? "ok" : "fail" }Here we use callRealMethod() to delegate the method invocation to the real object.
Note that we don’t have to pass the message argument along; this is taken care of automatically. callRealMethod()
returns the real invocation’s result, but in this example we opted to return our own result instead.
If we had wanted to pass a different message to the real method, we could have used callRealMethodWithArgs("changed message").
Please note that while semantically both callRealMethod() and callRealMethodWithArgs(…) only make sense with spies,
technically you can also call these methods on mock or stub objects, kind of turning them into (pseudo) spy objects
"through the backdoor". The only precondition is that the mocked/stubbed object actually has a real method implementation,
i.e. for interface mocks there must be a default method, for class mocks there must be a (non-abstract) original method.
Partial Mocks
(Think twice before using this feature. It might be better to change the design of the code under specification.)
Spies can also be used as partial mocks:
// this is now the object under specification, not a collaborator
MessagePersister persister = Spy {
// stub a call on the same object
isPersistable(_) >> true
}
when:
persister.receive("msg")
then:
// demand a call on the same object
1 * persister.persist("msg")Groovy Mocks
So far, all the mocking features we have seen work the same no matter if the calling code is written in Java or Groovy.
By leveraging Groovy’s dynamic capabilities, Groovy mocks offer some additional features specifically for testing Groovy code.
They are created with the MockingApi.GroovyMock(), MockingApi.GroovyStub(), and MockingApi.GroovySpy() factory methods.
|
Tip
|
When Should Groovy Mocks be Favored over Regular Mocks? Groovy mocks should be used when the code under specification is written in Groovy and some of the unique Groovy mock features are needed. When called from Java code, Groovy mocks will behave like regular mocks. Note that it isn’t necessary to use a Groovy mock merely because the code under specification and/or mocked type is written in Groovy. Unless you have a concrete reason to use a Groovy mock, prefer a regular mock. |
Mocking Dynamic Methods
All Groovy mocks implement the GroovyObject interface. They support the mocking and stubbing of
dynamic methods as if they were physically declared methods:
Subscriber subscriber = GroovyMock()
1 * subscriber.someDynamicMethod("hello")Mocking All Instances of a Type
(Think twice before using this feature. It might be better to change the design of the code under specification.)
Usually, Groovy mocks need to be injected into the code under specification just like regular mocks. However, when a Groovy mock is created as global, it automagically replaces all real instances of the mocked type for the duration of the feature method:[6]
def publisher = new Publisher()
publisher << new RealSubscriber() << new RealSubscriber()
RealSubscriber anySubscriber = GroovyMock(global: true)
when:
publisher.publish("message")
then:
2 * anySubscriber.receive("message")Here, we set up the publisher with two instances of a real subscriber implementation. Then we create a global mock of the same type. This reroutes all method calls on the real subscribers to the mock object. The mock object’s instance isn’t ever passed to the publisher; it is only used to describe the interaction.
|
Note
|
A global mock can only be created for a class type. It effectively replaces all instances of that type for the duration of the feature method. |
Since global mocks have a somewhat, well, global effect, it’s often convenient
to use them together with GroovySpy. This leads to the real code getting
executed unless an interaction matches, allowing you to selectively listen
in on objects and change their behavior just where needed.
Mocking Constructors
(Think twice before using this feature. It might be better to change the design of the code under specification.)
Global mocks support mocking of constructors:
RealSubscriber anySubscriber = GroovySpy(global: true)
1 * new RealSubscriber("Fred")Since we are using a spy, the object returned from the constructor call remains unchanged. To change which object gets constructed, we can stub the constructor:
new RealSubscriber("Fred") >> new RealSubscriber("Barney")Now, whenever some code tries to construct a subscriber named Fred, we’ll construct a subscriber named Barney instead.
Mocking Static Methods
(Think twice before using this feature. It might be better to change the design of the code under specification.)
Global mocks support mocking and stubbing of static methods:
RealSubscriber anySubscriber = GroovySpy(global: true)
1 * RealSubscriber.someStaticMethod("hello") >> 42The same works for dynamic static methods.
When a global mock is used solely for mocking constructors and static methods, the mock’s instance isn’t really needed. In such a case one can just write:
GroovySpy(RealSubscriber, global: true)Advanced Features
Most of the time you shouldn’t need these features. But if you do, you’ll be glad to have them.
A la Carte Mocks
At the end of the day, the Mock(), Stub(), and Spy() factory methods are just canned ways to
create mock objects with a certain configuration. If you want more fine-grained control over a mock’s configuration,
have a look at the org.spockframework.mock.IMockConfiguration interface. All properties of this interface
[7]
can be passed as named arguments to the Mock() method. For example:
def person = Mock(name: "Fred", type: Person, defaultResponse: ZeroOrNullResponse.INSTANCE, verified: false)Here, we create a mock whose default return values match those of a Mock(), but whose invocations aren’t
verified (as for a Stub()). Instead of passing ZeroOrNullResponse, we could have supplied our own custom
org.spockframework.mock.IDefaultResponse for responding to unexpected method invocations.
Detecting Mock Objects
To find out whether a particular object is a Spock mock object, use a org.spockframework.mock.MockUtil:
MockUtil mockUtil = new MockUtil()
List list1 = []
List list2 = Mock()
expect:
!mockUtil.isMock(list1)
mockUtil.isMock(list2)An util can also be used to get more information about a mock object:
IMockObject mock = mockUtil.asMock(list2)
expect:
mock.name == "list2"
mock.type == List
mock.nature == MockNature.MOCKFurther Reading
If you would like to dive deeper into interaction-based testing, we recommend the following resources:
- Endo-Testing: Unit Testing with Mock Objects
-
Paper from the XP2000 conference that introduces the concept of mock objects.
- Mock Roles, not Objects
-
Paper from the OOPSLA2004 conference that explains how to do mocking right.
- Mocks Aren’t Stubs
-
Martin Fowler’s take on mocking.
- Growing Object-Oriented Software Guided by Tests
-
TDD pioneers Steve Freeman and Nat Pryce explain in detail how test-driven development and mocking work in the real world.
Extensions
Spock comes with a powerful extension mechanism, which allows to hook into a spec’s lifecycle to enrich or alter its behavior. In this chapter, we will first learn about Spock’s built-in extensions, and then dive into writing custom extensions.
Spock Configuration File
Some extensions can be configured with options in a Spock configuration file. The description for each extension will
mention how it can be configured. All those configurations are in a Groovy file that usually is called
SpockConfig.groovy. Spock first searches for a custom location given in a system property called spock.configuration
which is then used either as classpath location or if not found as file system location if it can be found there,
otherwise the default locations are investigated for a configuration file. Next it searches for the SpockConfig.groovy
in the root of the test execution classpath. If there is also no such file, you can at last have a SpockConfig.groovy
in your Spock user home. This by default is the directory .spock within your home directory, but can be changed using
the system property spock.user.home or if not set the environment property SPOCK_USER_HOME.
Stack Trace Filtering
You can configure Spock whether it should filter stack traces or not by using the configuration file. The default value
is true.
runner {
filterStackTrace false
}Parallel Execution Configuration
runner {
parallel {
//...
}
}See the Parallel Execution section for a detailed description.
Built-In Extensions
Most of Spock’s built-in extensions are annotation-driven. In other words, they are triggered by annotating a
spec class or method with a certain annotation. You can tell such an annotation by its @ExtensionAnnotation
meta-annotation.
Ignore
To temporarily prevent a feature method from getting executed, annotate it with spock.lang.Ignore:
@Ignore
def "my feature"() { ... }For documentation purposes, a reason can be provided:
@Ignore("TODO")
def "my feature"() { ... }To ignore a whole specification, annotate its class:
@Ignore
class MySpec extends Specification { ... }In most execution environments, ignored feature methods and specs will be reported as "skipped".
By default, @Ignore will only affect the annotated specification, by setting inherited to true you can configure it to apply to sub-specifications as well:
@Ignore(inherited = true)
class MySpec extends Specification { ... }
class MySubSpec extends MySpec { ... }Care should be taken when ignoring feature methods in a spec class annotated with spock.lang.Stepwise since
later feature methods may depend on earlier feature methods having executed.
IgnoreRest
To ignore all but a (typically) small subset of methods, annotate the latter with spock.lang.IgnoreRest:
def "I'll be ignored"() { ... }
@IgnoreRest
def "I'll run"() { ... }
def "I'll also be ignored"() { ... }@IgnoreRest is especially handy in execution environments that don’t provide an (easy) way to run a subset of methods.
Care should be taken when ignoring feature methods in a spec class annotated with spock.lang.Stepwise since
later feature methods may depend on earlier feature methods having executed.
IgnoreIf
To ignore a feature method or specification under certain conditions, annotate it with spock.lang.IgnoreIf,
followed by a predicate and an optional reason:
@IgnoreIf({ System.getProperty("os.name").toLowerCase().contains("windows") })
def "I'll run everywhere but on Windows"() {Precondition Context
To make predicates easier to read and write, the following properties are available inside the closure:
sys-
A map of all system properties
env-
A map of all environment variables
os-
Information about the operating system (see
spock.util.environment.OperatingSystem) jvm-
Information about the JVM (see
spock.util.environment.Jvm) shared-
The shared specification instance, only shared fields will have been initialized. If this property is used, then the whole annotated element cannot be skipped up-front without initializing the shared instance.
instance-
The specification instance, if instance fields, shared fields, or instance methods are needed. If this property is used, the whole annotated element cannot be skipped up-front without executing fixtures, data providers and similar. Instead, the whole workflow is followed up to the feature method invocation, where then the closure is checked, and it is decided whether to abort the specific iteration or not.
data-
A map of all the data variables for the current iteration. Similar to
instancethis will run the whole workflow and only skip individual iterations.
Using the os property, the previous example can be rewritten as:
@IgnoreIf({ os.windows })
def "I will run everywhere but on Windows"() {You can also give an optional reason why the given feature or specification is to be ignored:
@IgnoreIf(value = { os.macOs }, reason = "No platform driver available")
def "For the given reason, I will not run on MacOS"() {By default, @IgnoreIf will only affect the annotated specification, by setting inherited to true you can configure it to apply to sub-specifications as well:
@IgnoreIf(value = { jvm.java8Compatible }, inherited = true)
abstract class Foo extends Specification {
}
class Bar extends Foo {
def "I won't run on Java 8 and above"() {
expect: true
}
}If multiple @IgnoreIf annotations are present, they are effectively combined with a logical "or".
The annotated element is skipped if any of the conditions evaluates to true:
@IgnoreIf({ os.windows })
@IgnoreIf({ jvm.java8 })
def "I'll run everywhere but on Windows or anywhere on Java 8"() {Care should be taken when ignoring feature methods in a spec class annotated with spock.lang.Stepwise since
later feature methods may depend on earlier feature methods having executed.
To use IDE support like code completion, you can also use the argument to the closure and have it typed as
org.spockframework.runtime.extension.builtin.PreconditionContext. This enables the IDE with type information
which is not available otherwise:
@IgnoreIf({ PreconditionContext it -> it.os.windows })
def "I will run everywhere but not on Windows"() {Using data.* to filter out iterations is especially helpful when using .combinations() to generate iterations.
@IgnoreIf({ os.windows })
@IgnoreIf({ data.a == 5 && data.b >= 6 })
def "I'll run everywhere but on Windows and only if a != 5 and b < 6"(int a, int b) {
// ...
where:
[a, b] << [(1..10), (1..8)].combinations()
}Also note that the condition is split into separate @IgnoreIf annotations so that they can be evaluated independently.
It is good practice ordering them based on their specificity, so that the least specific one is evaluated first, that is from static to shared to instance.
If you need to combine the conditions in a single @IgnoreIf annotation, you should order them from least specific to most specific inside as well.
Requires
To execute a feature method under certain conditions, annotate it with spock.lang.Requires,
followed by a predicate:
@Requires({ os.windows })
def "I'll only run on Windows"() {Requires works exactly like IgnoreIf, except that the predicate is inverted. In general, it is preferable
to state the conditions under which a method gets executed, rather than the conditions under which it gets ignored.
If multiple @Requires annotations are present, they are effectively combined with a logical "and".
The annotated element is skipped if any of the conditions evaluates to false:
@Requires({ os.windows })
@Requires({ jvm.java8 })
def "I'll run only on Windows with Java 8"() {PendingFeature
To indicate that the feature is not fully implemented yet and should not be reported as error, annotate it with spock.lang.PendingFeature.
The use case is to annotate tests that can not yet run but should already be committed.
The main difference to Ignore is that the test are executed, but test failures are ignored.
If the test passes without an error, then it will be reported as failure since the PendingFeature annotation should be removed.
This way the tests will become part of the normal tests instead of being ignored forever.
Groovy has the groovy.transform.NotYetImplemented annotation which is similar but behaves a differently.
-
it will mark failing tests as passed
-
if at least one iteration of a data-driven test passes it will be reported as error
PendingFeature:
-
it will mark failing tests as skipped
-
if at least one iteration of a data-driven test fails it will be reported as skipped
-
if every iteration of a data-driven test passes it will be reported as error
@PendingFeature
def "not implemented yet"() { ... }PendingFeatureIf
To conditionally indicate that a feature is not fully implemented, and should not be reported as an error you can annotate
it as spock.lang.PendingFeatureIf and include a precondition similar to IgnoreIf or Requires
If the conditional expression passes it behaves the same way as PendingFeature, otherwise it does nothing.
For instance, annotating a feature as @PendingFeatureIf({ false }) effectively does nothing, but annotating it as
@PendingFeatureIf({ true }) behaves the same was as if it was marked as @PendingFeature
If applied to a data driven feature, the closure can also access the data variables. If the closure does not reference any actual data variables, the whole feature is deemed pending and only if all iterations become successful will be marked as failing. But if the closure actually does reference valid data variables, the individual iterations where the condition holds are deemed pending and each will individually fail as soon as it would be successful without this annotation.
@PendingFeatureIf({ os.windows })
def "I'm not yet implemented on windows, but I am on other operating systems"() {
@PendingFeatureIf({ sys.targetEnvironment == "prod" })
def "This feature isn't deployed out to production yet, and isn't expected to pass"() {It is also supported to have multiple @PendingFeatureIf annotations or a mixture of @PendingFeatureIf and
@PendingFeature, for example to ignore certain exceptions only under certain conditions.
@PendingFeature(exceptions = UnsupportedOperationException)
@PendingFeatureIf(
exceptions = IllegalArgumentException,
value = { os.windows },
reason = 'Does not yet work on Windows')
@PendingFeatureIf(
exceptions = IllegalAccessException,
value = { jvm.java8 },
reason = 'Does not yet work on Java 8')
def "I have various problems in certain situations"() {Stepwise
To execute features in the order that they are declared, annotate a spec class with spock.lang.Stepwise:
@Stepwise
class RunInOrderSpec extends Specification {
def "I run first"() { expect: true }
def "I run second"() { expect: false }
def "I will be skipped"() { expect: true }
}Stepwise only affects the class carrying the annotation; not sub or super classes. Features after the first
failure are skipped.
Stepwise does not override the behaviour of annotations such as Ignore, IgnoreRest, and IgnoreIf, so care
should be taken when ignoring feature methods in spec classes annotated with Stepwise.
|
Note
|
This will also set the execution mode to SAME_THREAD, see Parallel Execution for more information.
|
Since Spock 2.2, Stepwise can be applied to data-driven feature methods, having the effect of executing them sequentially (even if concurrent test mode is active) and to skip subsequent iterations if one iteration fails:
class SkipAfterFailingIterationSpec extends Specification {
@Stepwise
def "iteration #count"() {
expect:
count != 3
where:
count << (1..5)
}
}This will pass for the first two iterations, fail on the third and skip the remaining two. Without Stepwise on feature method level, the third iteration would fail and the remaining 4 iterations would pass.
|
Note
|
For backward compatibility with Spock versions prior to 2.2, applying the annotation on spec level will not automatically skip subsequent feature method iterations upon failure in a previous iteration. If you want that in addition to (or instead of) step-wise spec mode, you do have to annotate each individual feature method you wish to have that capability. This also conforms to the principle that if you want to skip tests under whatever conditions, you ought to document your intent explicitly. |
Timeout
To fail a feature method, fixture, or class that exceeds a given execution duration, use spock.lang.Timeout,
followed by a duration, and optionally a time unit. The default time unit is seconds.
When applied to a feature method, the timeout is per execution of one iteration, excluding time spent in fixture methods:
@Timeout(5)
def "I fail if I run for more than five seconds"() { ... }
@Timeout(value = 100, unit = TimeUnit.MILLISECONDS)
def "I better be quick" { ... }Applying Timeout to a spec class has the same effect as applying it to each feature that is not already annotated
with Timeout, excluding time spent in fixtures:
@Timeout(10)
class TimedSpec extends Specification {
def "I fail after ten seconds"() { ... }
def "Me too"() { ... }
@Timeout(value = 250, unit = MILLISECONDS)
def "I fail much faster"() { ... }
}When applied to a fixture method, the timeout is per execution of the fixture method.
When a timeout is reported to the user, the stack trace shown reflects the execution stack of the test framework when the timeout was exceeded.
Retry
The @Retry extensions can be used for flaky integration tests, where remote systems can fail sometimes.
By default it retries an iteration 3 times with 0 delay if either an Exception or AssertionError has been thrown, all this is configurable.
In addition, an optional condition closure can be used to determine if a feature should be retried.
It also provides special support for data driven features, offering to either retry all iterations or just the failing ones.
class FlakyIntegrationSpec extends Specification {
@Retry
def retry3Times() { ... }
@Retry(count = 5)
def retry5Times() { ... }
@Retry(exceptions=[IOException])
def onlyRetryIOException() { ... }
@Retry(condition = { failure.message.contains('foo') })
def onlyRetryIfConditionOnFailureHolds() { ... }
@Retry(condition = { instance.field != null })
def onlyRetryIfConditionOnInstanceHolds() { ... }
@Retry
def retryFailingIterations() {
...
where:
data << sql.select()
}
@Retry(mode = Retry.Mode.FEATURE)
def retryWholeFeature() {
...
where:
data << sql.select()
}
@Retry(delay = 1000)
def retryAfter1000MsDelay() { ... }
}Retries can also be applied to spec classes which has the same effect as applying it to each feature method that isn’t already annotated with {@code Retry}.
@Retry
class FlakyIntegrationSpec extends Specification {
def "will be retried with config from class"() {
...
}
@Retry(count = 5)
def "will be retried using its own config"() {
...
}
}A {@code @Retry} annotation that is declared on a spec class is applied to all features in all subclasses as well, unless a subclass declares its own annotation. If so, the retries defined in the subclass are applied to all feature methods declared in the subclass as well as inherited ones.
Given the following example, running FooIntegrationSpec will execute both inherited and foo with one retry.
Running BarIntegrationSpec will execute inherited and bar with two retries.
@Retry(count = 1)
abstract class AbstractIntegrationSpec extends Specification {
def inherited() {
...
}
}
class FooIntegrationSpec extends AbstractIntegrationSpec {
def foo() {
...
}
}
@Retry(count = 2)
class BarIntegrationSpec extends AbstractIntegrationSpec {
def bar() {
...
}
}Check RetryFeatureExtensionSpec for more examples.
Use
To activate one or more Groovy categories within the scope of a feature method or spec, use spock.util.mop.Use:
class ListExtensions {
static avg(List list) { list.sum() / list.size() }
}
class UseDocSpec extends Specification {
@Use(ListExtensions)
def "can use avg() method"() {
expect:
[1, 2, 3].avg() == 2
}
}This can be useful for stubbing of dynamic methods, which are usually provided by the runtime environment (e.g. Grails). It has no effect when applied to a helper method. However, when applied to a spec class, it will also affect its helper methods.
To use multiple categories, you can either give multiple categories to the value attribute
of the annotation or you can apply the annotation multiple times to the same target.
|
Note
|
This will also set the execution mode to SAME_THREAD if applied on a Specification, see Parallel Execution for more information.
|
ConfineMetaClassChanges
To confine meta class changes to the scope of a feature method or spec class, use spock.util.mop.ConfineMetaClassChanges:
@Stepwise
class ConfineMetaClassChangesDocSpec extends Specification {
@ConfineMetaClassChanges(String)
def "I run first"() {
when:
String.metaClass.someMethod = { delegate }
then:
String.metaClass.hasMetaMethod('someMethod')
}
def "I run second"() {
when:
"Foo".someMethod()
then:
thrown(MissingMethodException)
}
}When applied to a spec class, the meta classes are restored to the state that they were in before setupSpec was executed,
after cleanupSpec is executed.
When applied to a feature method, the meta classes are restored to as they were after setup was executed,
before cleanup is executed.
To confine meta class changes for multiple classes, you can either give multiple classes to the value attribute
of the annotation or you can apply the annotation multiple times to the same target.
|
Caution
|
Temporarily changing the meta classes is only safe when specs are run in a single thread per JVM. Even though many execution environments do limit themselves to one thread per JVM, keep in mind that Spock cannot enforce this. |
|
Note
|
This will acquire a READ_WRITE lock for Resources.META_CLASS_REGISTRY, see Parallel Execution for more information.
|
RestoreSystemProperties
Saves system properties before the annotated feature method (including any setup and cleanup methods) gets run, and restores them afterwards.
Applying this annotation to a spec class has the same effect as applying it to all its feature methods.
@RestoreSystemProperties
def "determines family based on os.name system property"() {
given:
System.setProperty('os.name', 'Windows 7')
expect:
OperatingSystem.current.family == OperatingSystem.Family.WINDOWS
}|
Caution
|
Temporarily changing the values of system properties is only safe when specs are run in a single thread per JVM. Even though many execution environments do limit themselves to one thread per JVM, keep in mind that Spock cannot enforce this. |
|
Note
|
This will acquire a READ_WRITE lock for Resources.SYSTEM_PROPERTIES, see Parallel Execution for more information.
|
AutoAttach
Automatically attaches a detached mock to the current Specification. Use this if there is no direct framework
support available. Spring and Guice dependency injection is automatically handled by the
Spring Module and Guice Module respectively.
AutoCleanup
Automatically clean up a field or property at the end of its lifetime by using spock.lang.AutoCleanup.
By default, an object is cleaned up by invoking its parameterless close() method. If some other
method should be called instead, override the annotation’s value attribute:
// invoke foo.dispose()
@AutoCleanup("dispose")
def fooIf multiple fields or properties are annotated with AutoCleanup, their objects are cleaned up sequentially, in reverse
field/property declaration order, starting from the most derived class class and walking up the inheritance chain.
If a cleanup operation fails with an exception, the exception is reported by default, and cleanup proceeds with the next
annotated object. To prevent cleanup exceptions from being reported, override the annotation’s quiet attribute:
@AutoCleanup(quiet = true)
def ignoreMyExceptionsTempDir
In order to generate a temporary directory for test and delete it after test, annotate a member field of type
java.io.File, java.nio.file.Path or untyped using def in a spec class (def will inject a Path).
Alternatively, you can annotate a field with a custom type that has a public constructor accepting either java.io.File or java.nio.file.Path as its single parameter (see FileSystemFixture for an example).
If the annotated field is @Shared, the temporary directory will be shared in the corresponding specification, otherwise every feature method and every iteration per parametrized feature method will have their own temporary directories:
// all features will share the same temp directory path1
@TempDir
@Shared
Path path1
// all features and iterations will have their own path2
@TempDir
File path2
// will be injected using java.nio.file.Path
@TempDir
def path3
// use a custom class that accepts java.nio.file.Path as sole constructor parameter
@TempDir
FileSystemFixture path4
def demo() {
expect:
path1 instanceof Path
path2 instanceof File
path3 instanceof Path
path4 instanceof FileSystemFixture
}If you want to customize the parent directory for temporary directories, you can use the Spock Configuration File.
If keep is set to true, Spock will not delete temporary directories after tests. The default value is taken from
system property spock.tempDir.keep or false, if undefined.
tempdir {
// java.nio.Path object, default null,
// which means system property "java.io.tmpdir"
baseDir Paths.get("/tmp")
// boolean, default is system property "spock.tempDir.keep"
keep true
}Title and Narrative
To attach a natural-language name to a spec, use spock.lang.Title:
@Title("This is easy to read")
class ThisIsHarderToReadSpec extends Specification {
...
}Similarly, to attach a natural-language description to a spec, use spock.lang.Narrative:
@Narrative("""
As a user
I want foo
So that bar
""")
class GiveTheUserFooSpec() { ... }See
To link to one or more references to external information related to a specification or feature, use spock.lang.See:
@See("https://spockframework.org/spec")
class SeeDocSpec extends Specification {
@See(["https://en.wikipedia.org/wiki/Levenshtein_distance", "https://www.levenshtein.net/"])
def "Even more information is available on the feature"() {
expect: true
}
@See("https://www.levenshtein.de/")
@See(["https://en.wikipedia.org/wiki/Levenshtein_distance", "https://www.levenshtein.net/"])
def "And even more information is available on the feature"() {
expect: true
}
}Issue
To indicate that a feature or spec relates to one or more issues in an external tracking system, use spock.lang.Issue:
@Issue("https://my.issues.org/FOO-1")
class IssueDocSpec extends Specification {
@Issue("https://my.issues.org/FOO-2")
def "Foo should do bar"() {
expect: true
}
@Issue(["https://my.issues.org/FOO-3", "https://my.issues.org/FOO-4"])
def "I have two related issues"() {
expect: true
}
@Issue(["https://my.issues.org/FOO-5", "https://my.issues.org/FOO-6"])
@Issue("https://my.issues.org/FOO-7")
def "I have three related issues"() {
expect: true
}
}If you have a common prefix URL for all issues in a project, you can use the Spock Configuration File to set it up
for all at once. If it is set, it is prepended to the value of the @Issue annotation when building the URL.
If the issueNamePrefix is set, it is prepended to the value of the @Issue annotation when building the name for the
issue.
report {
issueNamePrefix 'Bug '
issueUrlPrefix 'https://my.issues.org/'
}Subject
To indicate one or more subjects of a spec, use spock.lang.Subject:
@Subject([Foo, Bar])
class SubjectDocSpec extends Specification {You can also use multiple @Subject annotations:
@Subject(Foo)
@Subject(Bar)
class SubjectDocSpec extends Specification {Additionally, Subject can be applied to fields and local variables:
@Subject
Foo myFooSubject currently has only informational purposes.
Rule
Spock understands @org.junit.Rule annotations on non-@Shared instance fields when the JUnit 4 module is included. The according rules are run at the
iteration interception point in the Spock lifecycle. This means that the rules before-actions are done before the
execution of setup methods and the after-actions are done after the execution of cleanup methods.
ClassRule
Spock understands @org.junit.ClassRule annotations on @Shared fields when the JUnit 4 module is included. The according rules are run at the
specification interception point in the Spock lifecycle. This means that the rules before-actions are done before the
execution of setupSpec methods and the after-actions are done after the execution of cleanupSpec methods.
Include and Exclude
Spock is capable of including and excluding specifications according to their classes, super-classes and interfaces and according to annotations that are applied to the specification.Spock is also capable of including and excluding individual features according to annotations that are applied to the feature method.The configuration for what to include or exclude is done according to the Spock Configuration File section.
import some.pkg.Fast
import some.pkg.IntegrationSpec
runner {
include Fast // could be either an annotation or a (base) class
exclude {
annotation some.pkg.Slow
baseClass IntegrationSpec
}
}Tags
Since version 2.2 Spock supports JUnit Platform tags. See the platform documentation for more information regarding valid tag values and how to configure your test execution to use them.
The @Tag annotation can be used to tag a spec or feature with one or more tags.
If applied on a spec, the tags are applied to all features in the spec.
Tags are inherited from parent specs.
If applied on a feature, the tags are applied to the feature.
@Tag("docs")
class TagDocSpec extends Specification {
def "has one tag"() {
expect: true
}
@Tag("other")
def "has two tags"() {
expect: true
}
}|
Note
|
JUnit Jupiter also has a @Tag annotation, but it will have no effect when used on a Specification.
|
Repeat until failure
Since version 2.3 the @RepeatUntilFailure annotation can be used to repeat a single feature until it fails or until it reaches the maxAttempts value.
This is intended to aid in manual debugging of flaky tests and should not be committed to source control.
Optimize Run Order
Spock can remember which features last failed and how often successively and also how long a feature needed to be
tested. For successive runs Spock will then first run features that failed at last run and first features that failed
more often successively. Within the previously failed or non-failed features Spock will run the fastest tests first.
This behaviour can be enabled according to the Spock Configuration File section. The default value is false.
runner {
optimizeRunOrder true
}Third-Party Extensions
You can find a list of third-party extensions in the Spock Wiki.
Writing Custom Extensions
There are two types of extensions that can be created for usage with Spock. These are global extensions and annotation driven local extensions. For both extension types you implement a specific interface which defines some callback methods. In your implementation of those methods you can set up the magic of your extension, for example by adding interceptors to various interception points that are described below.
It depends on your use case which type of annotation you create. If you want to do something once during the Spock run - at the start or end - or want to apply something to all executed specifications without the user of the extension having to do anything besides including your extension in the classpath, then you should opt for a global extension. If you instead want to apply your magic only by choice of the user, then you should implement an annotation driven local extension.
Global Extensions
To create a global extension you need to create a class that implements the interface IGlobalExtension and put its
fully-qualified class name in a file META-INF/services/org.spockframework.runtime.extension.IGlobalExtension in the
class path. As soon as these two conditions are satisfied, the extension is automatically loaded and used when Spock is
running.
IGlobalExtension has the following three methods:
start()-
This is called once at the very start of the Spock execution.
visitSpec(SpecInfo spec)-
This is called once for each specification. In this method you can prepare a specification with your extension magic, like attaching interceptors to various interception points as described in the chapter Interceptors.
stop()-
This is called at least once at the very end of the Spock execution.
Annotation Driven Local Extensions
To create an annotation driven local extension you need to create a class implementing the interface
IAnnotationDrivenExtension. As type argument to the interface you need to supply an annotation class having
@Retention set to RUNTIME, @Target set to one or more of FIELD, METHOD, and TYPE - depending on where you
want your annotation to be applicable - and @ExtensionAnnotation applied, with the IAnnotationDrivenExtension class
as argument. Of course the annotation class can have some attributes with which the user can further configure the
behaviour of the extension for each annotation application.
Your annotation can be applied to a specification, a feature method, a fixture method or a field. On all other places
like helper methods or other places if the @Target is set accordingly, the annotation will be ignored and has no
effect other than being visible in the source code, except you check its existence in other places yourself.
Since Spock 2.0 your annotation can also be defined as @Repeatable and applied multiple times to the same target.
IAnnotationDrivenExtension has visit…Annotations methods that are called by Spock with all annotations of the
extension applied to the same target. Their default implementations will then call the respective singular
visit…Annotation method once for each annotation. If you want a repeatable annotation that is compatible with
Spock before 2.0 you need to make the container annotation an extension annotation itself and handle all cases
accordingly, but you need to make sure to only handle the container annotation if Spock version is before 2.0,
or your annotations might be handled twice. Be aware that the repeatable annotation can be attached to the target
directly, inside the container annotation or even both if the user added the container annotation manually
and also attached one annotation directly.
IAnnotationDrivenExtension has the following nine methods, where in each you can prepare a specification with your
extension magic, like attaching interceptors to various interception points as described in the chapter
Interceptors:
visitSpecAnnotations(List<T> annotations, SpecInfo spec)-
This is called once for each specification where the annotation is applied one or multiple times with the annotation instances as first parameter, and the specification info object as second parameter. The default implementation calls
visitSpecAnnotationonce for each given annotation. visitSpecAnnotation(T annotation, SpecInfo spec)-
This is used as singular delegate for
visitSpecAnnotationsand is otherwise not called by Spock directly. The default implementation throws an exception. visitFieldAnnotations(List<T> annotations, FieldInfo field)-
This is called once for each field where the annotation is applied one or multiple times with the annotation instances as first parameter, and the field info object as second parameter. The default implementation calls
visitFieldAnnotationonce for each given annotation. visitFieldAnnotation(T annotation, FieldInfo field)-
This is used as singular delegate for
visitFieldAnnotationsand is otherwise not called by Spock directly. The default implementation throws an exception. visitFixtureAnnotations(List<T> annotations, MethodInfo fixtureMethod)-
This is called once for each fixture method where the annotation is applied one or multiple times with the annotation instances as first parameter, and the fixture method info object as second parameter. The default implementation calls
visitFixtureAnnotationonce for each given annotation. visitFixtureAnnotation(T annotation, MethodInfo fixtureMethod)-
This is used as singular delegate for
visitFixtureAnnotationsand is otherwise not called by Spock directly. The default implementation throws an exception. visitFeatureAnnotations(List<T> annotations, FeatureInfo feature)-
This is called once for each feature method where the annotation is applied one or multiple times with the annotation instances as first parameter, and the feature info object as second parameter. The default implementation calls
visitFeatureAnnotationonce for each given annotation. visitFeatureAnnotation(T annotation, FeatureInfo feature)-
This is used as singular delegate for
visitFeatureAnnotationsand is otherwise not called by Spock directly. The default implementation throws an exception. visitSpec(SpecInfo spec)-
This is called once for each specification within which the annotation is applied to at least one of the supported places like defined above. It gets the specification info object as sole parameter. This method is called after all other methods of this interface for each applied annotation are processed.
Configuration Objects
You can add own sections in the Spock Configuration File for your extension by creating POJOs or POGOs that are
annotated with @ConfigurationObject and have a default constructor (either implicitly or explicitly). The argument to
the annotation is the name of the top-level section that is added to the Spock configuration file syntax. The default
values for the configuration options are defined in the class by initializing the fields at declaration time or in the
constructor. In the Spock configuration file those values can then be edited by the user of your extension.
|
Note
|
It is an error to have multiple configuration objects with the same name, so choose wisely if you pick one and probably prefix it with some package-like name to minimize the risk for name clashes with other extensions or the core Spock code. |
To use the values of the configuration object in your extension, you can either use constructor injection or field injection.
-
To use constructor injection just define a constructor with one or more configuration object parameters.
-
To use field injection just define an uninitialized non-final instance field of that type.
Spock will then automatically create exactly one instance of the configuration object per Spock run, apply the
settings from the configuration file to it (before the start() methods of global extensions are called) and inject
that instance into the extension class instances.
|
Note
|
Constructor injection has a higher priority than field injection and Spock won’t inject any fields if it finds a suitable constructor. If you want to support both Spock 1.x and 2.x you can either use only field injection (Spock 1.x only supports field injection), or you can have both a default constructor and an injectable constructor, this way Spock 2.x will use constructor injection and Spock 1.x will use field injection. |
If a configuration object should be used exclusively in an annotation driven local extension you must register it in
META-INF/services/spock.config.ConfigurationObject.
This is similar to a global extension, put the fully-qualified class name of the annotated class on a new line in the file.
This will cause the configuration object to properly get initialized and populated with the settings from the configuration file.
However, if the configuration object is used in a global extension, you can also use it just fine in an annotation driven local
extension. If the configuration object is only used in an annotation driven local extension, you will get an exception
when then configuration object is to be injected into the extension, and you will also get an error when the
configuration file is evaluated, and it contains the section, as the configuration object is not properly registered yet.
Interceptors
For applying the magic of your extension, there are various interception points, where you can attach interceptors from the extension methods described above to hook into the Spock lifecycle. For each interception point there can of course be multiple interceptors added by arbitrary Spock extensions (shipped or 3rd party). Their order currently depends on the order they are added, but there should not be made any order assumptions within one interception point.
An ellipsis in the figure means that the block before it can be repeated an arbitrary amount of times.
The … method interceptors are of course only run if there are actual methods of this type to be executed (the white
boxes) and those can inject parameters to be given to the method that will be run.
The difference between shared initializer interceptor and shared initializer method interceptor and between initializer
interceptor and initializer method interceptor - as there can be at most one of those methods each - is, that there are
only the two methods if there are @Shared, respectively non-@Shared, fields that get values assigned at declaration
time. The compiler will put those initializations in a generated method and call it at the proper place in the
lifecycle. So if there are no such initializations, no method is generated and thus the method interceptor is never
called. The non-method interceptors are always called at the proper place in the lifecycle to do work that has to be
done at that time.
To create an interceptor to be attached to an interception point, you need to create a class that implements the
interface IMethodInterceptor. This interface has the sole method intercept(IMethodInvocation invocation). The
invocation parameter can be used to get and modify the current state of execution. Each interceptor must call the
method invocation.proceed(), which will go on in the lifecycle, except you really want to prevent further execution of
the nested elements like shown in the figure above. But this should be a very rare use case.
If you write an interceptor that can be used at different interception points and should do different work at different
interception points, there is also the convenience class AbstractMethodInterceptor, which you can extend and which
provides various methods for overriding that are called for the various interception points. Most of these methods have
a double meaning, like interceptSetupMethod which is called for the setup interceptor and the setup method
interceptor. If you attach your interceptor to both of them and need a differentiation, you can check for
invocation.method.reflection, which will be set in the method interceptor case and null otherwise. Alternatively you
can of course build two different interceptors or add a parameter to your interceptor and create two instances, telling
each at addition time whether it is attached to the method interceptor or the other one.
class I extends AbstractMethodInterceptor { I(def s) {} }
// On SpecInfo
specInfo.addSharedInitializerInterceptor new I('shared initializer')
specInfo.sharedInitializerMethod?.addInterceptor new I('shared initializer method')
specInfo.addInterceptor new I('specification')
specInfo.addSetupSpecInterceptor new I('setup spec')
specInfo.setupSpecMethods*.addInterceptor new I('setup spec method')
specInfo.allFeatures*.addInterceptor new I('feature')
specInfo.addInitializerInterceptor new I('initializer')
specInfo.initializerMethod?.addInterceptor new I('initializer method')
specInfo.allFeatures*.addIterationInterceptor new I('iteration')
specInfo.addSetupInterceptor new I('setup')
specInfo.setupMethods*.addInterceptor new I('setup method')
specInfo.allFeatures*.featureMethod*.addInterceptor new I('feature method')
specInfo.addCleanupInterceptor new I('cleanup')
specInfo.cleanupMethods*.addInterceptor new I('cleanup method')
specInfo.addCleanupSpecInterceptor new I('cleanup spec')
specInfo.cleanupSpecMethods*.addInterceptor new I('cleanup spec method')
specInfo.allFixtureMethods*.addInterceptor new I('fixture method')
// on FeatureInfo
featureInfo.addInterceptor new I('feature')
featureInfo.addIterationInterceptor new I('iteration')
featureInfo.featureMethod.addInterceptor new I('feature method')Injecting Method Parameters
If your interceptor should support custom method parameters for wrapped methods, this can be done by modifying
invocation.arguments. Two use cases for this would be a mocking framework that can inject method parameters that are
annotated with a special annotation, or some test helper that injects objects of a specific type that are created and
prepared for usage automatically.
When called from at least Spock 2.0, the arguments array will always have the size of the method parameter count,
so you can directly set the arguments you want to set. You cannot change the size of the arguments array either.
All parameters that did not yet get any value injected, either from data variables or some extension, will have the
value MethodInfo.MISSING_ARGUMENT and if any of those remain, after all interceptors were run, an exception will be
thrown.
|
Note
|
When your extension might be used with a version before Spock 2.0, the Inject Method Parameters
|
|
Note
|
Pre Spock 2.0 only: When using data driven features (methods with a
Of course, you can also make your extension only inject a value if none is set already, as the for this simply check whether Data Driven Feature with Injected Parameter pre Spock 2.0
Data Driven Feature with Injected Parameter post Spock 2.0
|
Utilities
Testing Time with MutableClock
When working with dates or time we often have the problem of writing stable tests.
Java only provides a FixedClock for testing.
However, often time related code has to deal with the change of time,
so a fixed clock is not enough or makes the test harder to follow.
The prerequisite for using both FixedClock and Spocks MutableClock is that the production code,
actually uses a configurable Clock and not just the parameterless Instant.now()
or the corresponding methods in the other java.time.* classes.
Example
public class AgeFilter implements Predicate<LocalDate> {
private final Clock clock;
private final int age;
public AgeFilter(Clock clock, int age) { // (1)
this.clock = clock;
this.age = age;
}
@Override
public boolean test(LocalDate date) {
return Period.between(date, LocalDate.now(clock)).getYears() >= age; // (2)
}
}-
Clockis injected via constructor -
Clockis used to get the current date
def "AgeFilter reacts to time"() {
given:
ZonedDateTime defaultTime = ZonedDateTime.of(2018, 6, 5, 0, 0, 0, 0, ZoneId.of('UTC'))
MutableClock clock = new MutableClock(defaultTime) // (1)
AgeFilter ageFilter = new AgeFilter(clock,18) // (2)
LocalDate birthday = defaultTime.minusYears(18).plusDays(1).toLocalDate()
expect:
!ageFilter.test(birthday) // (3)
when:
clock + Duration.ofDays(1) // (4)
then:
ageFilter.test(birthday) // (5)
}-
MutableClockcreated with a well known time -
Clockis injected via constructor -
ageis less than18so the result isfalse -
the clock is advanced by one day
-
ageis equal to18so the result istrue
There are many more ways to modify MutableClock just have a look at the JavaDocs, or the test code spock.util.time.MutableClockSpec.
Collection Conditions
Sometimes, you want to assert the elements of a collection regardless of their order.
The Groovy way to do this is to cast both to Set, i.e. x as Set == [1, 2, 3] as Set.
While this works, it is very noisy.
Since Spock 2.1 you can use two new conditions:
-
x =~ [1, 2, 3]is a lenient match, i.e., checking that x contains at least one instance of every item in the list (same semantics as casting both toSetbefore comparing). -
x ==~ [1, 2, 3, 3]is a strict match, i.e., checking that x contains exactly the items in the list regardless of their order (using Hamcrest’scontainsInAnyOrderunder the hood).
Lenient Match
def x = [2, 2, 1, 3, 3]
assert x =~ [4, 1, 2]x =~ [4, 1, 2]
| |
| false
| 2 differences (66% similarity, 1 missing, 1 extra)
| missing: [4]
| extra: [3]
[2, 1, 3]Strict Match
def x = [2, 2, 1, 3, 3]
assert x ==~ [4, 1, 2]x ==~ [4, 1, 2]
| |
| false
[2, 2, 1, 3, 3]
Expected: iterable with items [<4>, <1>, <2>] in any order
but: not matched: (2)|
Note
|
Both operands must be Iterable for this to work.
Otherwise, it will be treated like the standard groovy find operator or match operators.
|
Interact with the file system using FileSystemFixture
In integration tests you often have to prepare the file system for a test.
For trivial cases like creating a single temp directory, you can use the @TempDir extension directly.
However, for more complex cases like creating a directory tree FileSystemFixture offers convenience and better readability.
Examples
@TempDir
FileSystemFixture fsFixture
def "FileSystemFixture can create a directory structure"() {
when:
fsFixture.create {
dir('src') {
dir('main') {
dir('groovy') {
file('HelloWorld.java') << 'println "Hello World"'
}
}
dir('test/resources') {
file('META-INF/MANIFEST.MF') << 'bogus entry'
copyFromClasspath('/org/spockframework/smoke/extension/SampleFile.txt')
}
}
}
then:
Files.isDirectory(fsFixture.resolve('src/main/groovy'))
Files.isDirectory(fsFixture.resolve('src/test/resources/META-INF'))
fsFixture.resolve('src/main/groovy/HelloWorld.java').text == 'println "Hello World"'
fsFixture.resolve('src/test/resources/META-INF/MANIFEST.MF').text == 'bogus entry'
fsFixture.resolve('src/test/resources/SampleFile.txt').text == 'HelloWorld\n'
}|
Tip
|
To get the nice Groovy methods for Path, you need to add a dependency on groovy-nio.
|
Parallel Execution
|
Warning
|
This is an experimental feature for Spock, which is based on the experimental implementation of parallel execution in the JUnit Platform. |
Parallel execution has the potential to reduce the overall test execution time. The actual achievable reduction will heavily depend on the respective codebase and can vary wildly.
By default, Spock runs tests sequentially with a single thread.
As of version 2.0, Spock supports parallel execution based on the JUnit Platform.
To enable parallel execution set the runner.parallel.enabled configuration to true.
See Spock Configuration File for general information about this file.
runner {
parallel {
enabled true
}
}|
Note
|
JUnit Jupiter also supports parallel execution, both rely on the JUnit Platform implementation, but function independently of each other. If you enable parallel execution in Spock it won’t affect Jupiter and vice versa. The JUnit Platform executes the test engines (Spock, Jupiter) sequentially, so there should not be any interference between engines. |
Execution modes
Spock supports two execution modes SAME_THREAD and CONCURRENT.
You can define the execution mode explicitly for a specification or feature via the @Execution annotation.
Otherwise, Spock will use the value of defaultSpecificationExecutionMode and defaultExecutionMode respectively, both have CONCURRENT as default value.
Certain extensions also set execution modes when they are applied.
-
defaultSpecificationExecutionModecontrols what execution mode a specification will use by default. -
defaultExecutionModecontrols what execution mode a feature and its iterations (if data driven) will use by default.

runner.parallel.enabled=false or SAME_THREAD Specifications, SAME_THREAD Features
CONCURRENT Specifications, CONCURRENT Features
CONCURRENT Specifications, SAME_THREAD Features
SAME_THREAD Specifications, CONCURRENT FeaturesExecution Hierarchy

-
The node
Same Threadwill run in the same thread as its parent. -
The node
Concurrentwill be executed in another thread, all concurrent nodes can execute in different threads from each other. -
The node
ResourceLock(READ)will be executed in another thread, but will also acquire aREAD-lock for a resource. -
The node
ResourceLock(READ_WRITE)will be executed in another thread, but will also acquire aREAD_WRITE-lock for a resource. -
The node
Same Thread with Lockwill run in the same thread as its parent thus inheriting the lock. -
The node
Data Driven Featurerepresents a data driven feature withData Driven Feature[1]andData Driven Feature[2]being the iterations. -
The node
Isolatedwill run exclusively, no other specifications or features will run at the same time.

Figure 7 shows the default case when parallel execution is disabled (runner.parallel.enabled=false) or when both specifications (defaultSpecificationExecutionMode) and features (defaultExecutionMode) are set to SAME_THREAD.

CONCURRENT Specifications, SAME_THREADFigure 8 shows the result of setting defaultSpecificationExecutionMode=CONCURRENT and defaultExecutionMode=SAME_THREAD, the specifications will run concurrently but all features will run in the same thread as their specification.

SAME_THREAD Specifications, CONCURRENT FeaturesFigure 9 shows the result of setting defaultSpecificationExecutionMode=SAME_THREAD and defaultExecutionMode=CONCURRENT, the specifications will run in the same thread, causing them to run one after the other.
The features inside a specification will run concurrently.

CONCURRENT Specifications, CONCURRENT FeaturesFigure 10 shows the result of setting defaultSpecificationExecutionMode=CONCURRENT and defaultExecutionMode=CONCURRENT, both specifications and features will run concurrently.
Execution Mode Inheritance
If nothing else is explicit configured, specifications will use defaultSpecificationExecutionMode and features use defaultExecutionMode.
However, this changes when you set the execution mode explicitly via @Execution.
Each node (specification, feature) checks first if it has an explicit execution mode set,
otherwise it will check its parents for an explicit setting and fall back to the respective defaults otherwise.
The following examples have defaultSpecificationExecutionMode=SAME_THREAD and defaultExecutionMode=SAME_THREAD.
If you invert the values SAME_THREAD and CONCURRENT in these examples you will get the inverse result.

SAME_THREAD Specifications, SAME_THREAD Features and explicit @Execution on FeaturesIn Figure 11 @Execution is applied on the features and those features and iterations will execute concurrently while the rest will execute in the same thread.

SAME_THREAD Specifications, SAME_THREAD Features and explicit @Execution on a SpecificationIn Figure 12 @Execution is applied on one specification causing the specification and all its features to run concurrently.
The features execute concurrently since they inherit the explicit execution mode from the specification.

SAME_THREAD Specifications, SAME_THREAD Features and explicit @Execution on Features and SpecificationsFigure 13 showcases the combined application of @Execution on a specification and some of its features.
As in the previous example the specification and its features will execute concurrently except testB1 since it has its own explicit execution mode set.
Resource Locks
With parallel execution comes a new set of challenges for testing, as shared state can be modified and consumed by multiple tests at the same time.
A simple example would be two features that test the use a system property, both setting it to a specific value in the respective given block and then executing the code to test the expected behavior.
If they run sequentially then both complete without issue. However, if the run at the same time both given blocks will run before the when blocks and one feature will fail since the system property did not contain the expected value.
The above example could simply be fixed if both features are part of the same specification by setting them to run in the same thread with @Execution(SAME_THREAD).
However, this is not really practicable when the features are in separate specifications.
To solve this issue Spock has support to coordinate access to shared resources via @ResourceLock.
With @ResourceLock you can define both a key and a mode. By default, @ResourceLock assumes ResourceAccessMode.READ_WRITE, but you can weaken it to ResourceAccessMode.READ.
-
ResourceAccessMode.READ_WRITEwill enforce exclusive access to the resource. -
ResourceAccessMode.READwill prevent anyREAD_WRITElocks, but will allow otherREADlocks.
READ-only locks will isolate tests from others that modify the shared resource, while at the same time allowing tests that also only read the resource to execute.
You should not modify the shared resource when you only hold a READ lock, otherwise the assurances don’t hold.
Certain extensions also set implicit locks when they are applied.

@ResourceLockLock inheritance
If a parent node has a READ_WRITE lock, it forces its children to run in the same thread.
As READ_WRITE locks cause serialized execution anyway, this is effectively not different from what would happen if the lock would be applied to every child directly.
However, if the parent node has only READ locks, then it allows parallel execution of its children.


Lock coarsening
To avoid deadlocks, Spock pulls up locks to the specification, when locks are defined on both the specification and features.
The Specification will then contain all defined locks.
If the features both had READ_WRITE and READ locks for the same resource, then the READ will be merged into the READ_WRITE.


Isolated Execution
Sometimes, you want to modify and test something that affects every other feature, you could put a READ @ResourceLock on every feature, but that is impractical.
The @Isolated extension enforces, that only this feature runs without any other features running at the same time.
You can think of this as an implicit global lock.
As with other locks, the features in an @Isolated specification will run in SAME_THREAD mode.
@Isolated can only be applied at the specification level so if you have a large specification and only need it for a few features,
you might want to consider splitting the spec into @Isolated and non isolated.

@Isolated executionParallel Thread Pool
With parallel execution enabled, specifications and features can execute concurrently.
You can control the size of the thread pool that executes the features.
Spock uses Runtime.getRuntime().availableProcessors() to determine the available processors.
-
dynamic(BigDecimal factor)- Computes the desired parallelism based on the number of available processors multiplied by thefactorand rounded down to the nearest integer. For example a factor of0.5will use half your processors. -
dynamicWithReservedProcessors(BigDecimal factor, int reservedProcessors)- Same asdynamicbut ensures that the given amount ofreservedProcessorsis not used. ThereservedProcessorsare counted against the available cores not the result of the factor. -
fixed(int parallelism)- Uses the given amount of threads. -
custom(int parallelism, int minimumRunnable, int maxPoolSize, int corePoolSize, int keepAliveSeconds)- Allows complete control over the threadpool. However, it should only be used when the other options are insufficient, and you need that extra bit of control. Check the Javadoc ofspock.config.ParallelConfigurationfor a detailed description the parameters.
By default, Spock uses dynamicWithReservedProcessors(1.0, 2) that is all your logical processors minus 2.
If the calculated parallelism is less than 2, then Spock will execute single threaded, basically the same as runner.parallel.enabled=false.
fixed settingrunner {
parallel {
enabled true
fixed(4)
}
}Modules
JUnit 4 Module
Integration with JUnit 4 features for Spock 2+ (which internally uses JUnit Platform - part of JUnit 5). Please add dependency org.spockframework:spock-junit4 to your project.
The module is required for:
-
running JUnit 4 rules and class ruless (
@Rule/@ClassRule) -
using JUnit 4’s test fixture annotations (
@BeforeClass,@Before,@After,@AfterClass)
|
Note
|
This module does its best to support old features from JUnit 4, however, users are encouraged to migrate to the native Spock counterparts. |
Guice Module
Integration with the Guice IoC container. Please add dependency org.spockframework:spock-guice to your project. For examples see the specs in the
codebase.
With Spock 1.2+ detached mocks are automatically attached to the Specification if they are injected via @Inject.
Spring Module
The Spring module enables integration with Spring TestContext Framework.
It supports the following spring annotations @ContextConfiguration and @ContextHierarchy. Furthermore, it supports the meta-annotation @BootstrapWith and so any annotation that is annotated with @BootstrapWith will also work, such as @SpringBootTest, @WebMvcTest. Please add dependency org.spockframework:spock-spring to your project.
Mocks
Spock 1.1 introduced the DetachedMockFactory and the SpockMockFactoryBean which allow the creation of Spock mocks outside of a specification.
|
Note
|
Although the mocks can be created outside of a specification, they only work properly inside the scope of a specification.
All interactions with them until they are attached to one, are handled by the default behavior and not recorded.
Furthermore, mocks can only be attached to one Specification instance at a time so keep that in mind when using multi-threaded executions
|
Java Config
class DetachedJavaConfig {
def mockFactory = new DetachedMockFactory()
@Bean
GreeterService serviceMock() {
return mockFactory.Mock(GreeterService)
}
@Bean
GreeterService serviceStub() {
return mockFactory.Stub(GreeterService)
}
@Bean
GreeterService serviceSpy() {
return mockFactory.Spy(GreeterServiceImpl)
}
@Bean
FactoryBean<GreeterService> alternativeMock() {
return new SpockMockFactoryBean(GreeterService)
}
}XML
Spock has spring namespace support, so if you declare the spock namespace with xmlns:spock="https://www.spockframework.org/spring" you get access to the convenience functions for creating mocks.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:spock="http://www.spockframework.org/spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.spockframework.org/spring https://www.spockframework.org/spring/spock.xsd">
<spock:mock id="serviceMock" class="org.spockframework.spring.docs.GreeterService"/> (1)
<spock:stub id="serviceStub" class="org.spockframework.spring.docs.GreeterService"/> (2)
<spock:spy id="serviceSpy" class="org.spockframework.spring.docs.GreeterServiceImpl"/> (3)
<bean id="someExistingBean" class="java.util.ArrayList"/> (4)
<spock:wrapWithSpy ref="someExistingBean"/> (4)
<bean id="alternativeMock" class="org.spockframework.spring.xml.SpockMockFactoryBean"> (5)
<constructor-arg value="org.spockframework.spring.docs.GreeterService"/>
<property name="mockNature" value="MOCK"/> (6)
</bean>
</beans>-
Creates a
Mock -
Creates a
Stub -
Creates a
Spy -
Wraps an existing bean with a
Spy. Fails fast if referenced bean is not found. -
If you don’t want to use the special namespace support you can create the beans via the
SpockMockFactoryBean -
The
mockNaturecan beMOCK,STUB, orSPYand defaults toMOCKif not declared.
Usage
To use the mocks just inject them like any other bean and configure them as usual.
@Autowired @Named('serviceMock')
GreeterService serviceMock
@Autowired @Named('serviceStub')
GreeterService serviceStub
@Autowired @Named('serviceSpy')
GreeterService serviceSpy
@Autowired @Named('alternativeMock')
GreeterService alternativeMock
def "mock service"() {
when:
def result = serviceMock.greeting
then:
result == 'mock me'
1 * serviceMock.getGreeting() >> 'mock me'
}
def "sub service"() {
given:
serviceStub.getGreeting() >> 'stub me'
expect:
serviceStub.greeting == 'stub me'
}
def "spy service"() {
when:
def result = serviceSpy.greeting
then:
result == 'Hello World'
1 * serviceSpy.getGreeting()
}
def "alternative mock service"() {
when:
def result = alternativeMock.greeting
then:
result == 'mock me'
1 * alternativeMock.getGreeting() >> 'mock me'
}Annotation driven
Spock 1.2 adds support for exporting mocks from a Specification into an ApplicationContext. This was inspired by
Spring Boot’s @MockBean(realised via Mockito) but adapted to fit into Spock style. It does not require any Spring Boot dependencies,
however it requires Spring Framework 4.3.5 or greater to work.
Using @SpringBean
Registers mock/stub/spy as a spring bean in the test context.
To use @SpringBean you have to use a strongly typed field def or Object won’t work. You also need to directly assign the
Mock/Stub/Spy to the field using the standard Spock syntax. You can even use the initializer blocks to define common behavior,
however they are only picked up once they are attached to the Specification.
@SpringBean definitions can replace existing Beans in your ApplicationContext.
|
Note
|
Spock’s @SpringBean actually creates a proxy in the ApplicationContext which forwards everything to the current
mock instance. The type of the proxy is determined by the type of the annotated field.
The proxy attaches itself to the current mock in the setup phase, that is why the mock must be created when the field is initialized. |
@SpringBean
Service1 service1 = Mock()
@SpringBean
Service2 service2 = Stub() {
generateQuickBrownFox() >> "blubb"
}
def "injection with stubbing works"() {
expect:
service2.generateQuickBrownFox() == "blubb"
}
def "mocking works was well"() {
when:
def result = service1.generateString()
then:
result == "Foo"
1 * service1.generateString() >> "Foo"
}|
Caution
|
As with Spring’s own @MockBean this will modify your ApplicationContext, and will create an unique context for your
Specification preventing it from being reused by Spring’s
Context Caching
outside of the current Specification.
If you are using a small context this won’t matter much, but if it is a heavy context you might want to use the other approaches, e.g., using the DetachedMockFactory.
|
Using @SpringSpy
If you want to spy on an existing bean, you can use the @SpringSpy annotation to wrap the bean in a spy.
As with @SpringBean the field must be of the type you want to spy on, however you cannot use an initializer.
@SpringSpy
Service2 service2
@Autowired
Service1 service1
def "default implementation is used"() {
expect:
service1.generateString() == "The quick brown fox jumps over the lazy dog."
}
def "mocking works was well"() {
when:
def result = service1.generateString()
then:
result == "Foo"
1 * service2.generateQuickBrownFox() >> "Foo"
}Using @StubBeans
@StubBeans registers plain Stub instances in an ApplicationContext.
Use this if you just need to satisfy some dependencies without actually doing anything with these stubs.
If you need to control the stubs, e.g., configure return values then use @SpringBean instead.
Like @SpringBean @StubBeans also replaced existing BeanDefinitions,so you can use it to remove real beans from an ApplicationContext.
@StubBeans can be replaced by @SpringBean, this can be useful if you need to replace some @StubBeans defined in a parent class.
@StubBeans(Service2)
@ContextConfiguration(classes = DemoMockContext)
class StubBeansExamples extends Specification {Spring Boot
The recommended way to use Spock mocks in @WebMvcTest or other @SpringBootTest-style tests,
is to use the @SpringBean and @SpringSpy annotations as shown above.
Alternatively you can use an embedded config annotated with @TestConfiguration and to create the mocks using the DetachedMockFactory.
@WebMvcTest
class WebMvcTestIntegrationSpec extends Specification {
@Autowired
MockMvc mvc
@Autowired
HelloWorldService helloWorldService
def "spring context loads for web mvc slice"() {
given:
helloWorldService.getHelloMessage() >> 'hello world'
expect: "controller is available"
mvc.perform(MockMvcRequestBuilders.get("/"))
.andExpect(status().isOk())
.andExpect(content().string("hello world"))
}
@TestConfiguration
static class MockConfig {
def detachedMockFactory = new DetachedMockFactory()
@Bean
HelloWorldService helloWorldService() {
return detachedMockFactory.Stub(HelloWorldService)
}
}
}For more examples see the specs in the codebase and boot examples.
Scopes
Spock ignores bean that is not a singleton (in the singleton scope) by default. To enable mocks to work for scoped beans
you need to add @ScanScopedBeans to the spec and make sure that the scope allows access to the bean during the setup phase.
|
Note
|
The request and session scope will throw exceptions by default, if there is no active request/session.
|
You can limit the scanning to certain scopes by using the value property of @ScanScopedBeans.
Shared fields injection
Due to certain limitations, injection into shared fields is not enabled by default but can be opted-in to.
Refer to javadoc of org.spockframework.spring.EnableSharedInjection for further information.
Tapestry Module
Integration with the Tapestry5 IoC container. Please add dependency org.spockframework:spock-tapestry to your project. For examples see the specs in the
codebase.
Unitils Module
Integration with the Unitils library. Please add dependency org.spockframework:spock-unitils to your project. For examples see the specs in the
codebase.
Grails Module
The Grails plugin has moved to its own GitHub project. It has legacy status and was last released for Spock 0.7 and Groovy versions 1.8 and 2.0, because it is no longer necessary.
|
Note
|
Grails 2.3 and higher have built-in Spock support and do not require a plugin. |
Release Notes
2.3 (2022-09-29)
-
Add RepeatUntilFailure extension #1522
-
Fix problem with TempDir failing when using a custom class that extends from
FileorPath#1519 -
Fix issue with
Objectmethods on interface spies #1529 -
Fix equality checking of Mocks that implement
Comparable#1323 -
Validate uniqueness of fixture methods per specification class #1521
|
Note
|
The changes to equality checking for Comparable mocks can lead to different behavior when no explicit compareTo interactions was defined.
For example, Groovy will use compareTo to check equality when classes implement Compareable.
Until now, the mock would return 0 for default invocations, which would lead to the objects being considered equal.
|
Thanks to all the contributors to this release: Jackson Popkin
2.2 (2022-08-31)
Thanks to all the contributors to this release: Alexander Kriegisch, Marcin Zajączkowski, Jonny Carter, alopukhov, Jerome Prinet, Matthew Moss, BJ Hargrave, konradczajka
2.2-M3 (2022-07-15)
-
Add support for
IterationSelectorto run individual iterations -
Update to JUnit 5.9.0-RC1
Thanks to all the contributors to this release: Marc Philipp
2.2-M2 (2022-07-15)
-
Add junit-platform
TestTagsupport with the @Tag extension #1467 -
Add
IDataDriverextension point and refactor data provider handling #1479 -
Add named deconstruction for multi variable datapipes. This might lead to changed behavior results if the data object implements
Mapbut supports both positionalgetAt(int)and namedgetAt(String)access. In earlier versions, the positional access was used, but now the named access will be used. #1463 -
Add custom class support to
@TempDir, you can use any class that has a singlejava.io.Fileorjava.nio.file.Pathas constructor parameter #1430 -
Improve
@Stepwisecan be applied to data-driven feature methods, having the effect of executing them sequentially (even if concurrent test mode is active) and to skip subsequent iterations is one iteration fails. #1442 -
Improve
EmbeddedSpecCompilerby making package declaration configurable inEmbeddedSpecCompiler -
Improve do not evaluate feature-skipping conditions for skipped specs #1459
-
Improve behavior when trying to run Spock with unsupported Groovy version in IDEA #1421
-
Improve Java 17 compatibility by using new
invokeDefaultinstead of reflection -
Fix compatibility with certain locales, for example
tr_TR#1414 -
Fix Spring 6 incompatibility #1428
-
Fix test reporting issue with Maven, where an error on the Specification level was not visible #1444
-
Fix context pollution in
IterationNode.around()#1441 -
Fix Discard unnecessary state in
ConfineMetaClassChangesInterceptor#1460 -
Fix make
EnableSharedInjectionpublic #1472 -
Fix gradle module metadata dependencies #1490
-
Remove runtime dependency on Jetbrains Annotations #1468
Thanks to all the contributors to this release: Alexander Kriegisch, Marcin Zajączkowski, Jonny Carter, alopukhov, Jerome Prinet, Matthew Moss, BJ Hargrave
2.2-M1 (2022-02-16)
-
Add Groovy 4 support #1382
No other changes to the 2.1 release.
Thanks to all the contributors to this release: Marcin Zajączkowski
2.1 (2022-02-15)
No functional changes to 2.1-M2.
Official Spock Logo
The Spock Framework Project has an official logo. Many thanks to Ayşe Altınsoy (@AltinsoyAyse) for creating the logo through many iterations.
Misc
-
Documentation fixes
-
Build maintenance
Thanks to all the contributors to this release: Marc Philipp, Miles Thomason, BJ Hargrave, Marcin Zajączkowski, Lőrinc Pap, Felipe Pedrosa, Marcin Świerczyński, Benedikt Ritter, Alexander Kriegisch, Jérôme Prinet, Pin Zhang
2.1-M2 (2021-11-12)
-
Fix issue with generated gradle module metadata that caused issues with consumers.
-
Update JUnit, ASM, ByteBuddy dependencies.
2.1-M1 (2021-11-12)
Highlights
-
Add support for selecting individual iterations via their unique ID (IDE support required). #1376
Breaking Changes
-
Add
data.support to conditional extensions #1360. This replaces the current behavior of accessing data variables without any prefix. See Precondition Context for more details.
Misc
-
Add exception translation to JUnit4 Rules #1342
-
Add option to omit feature name from iterations #1386 and add additional Special Tokens to unroll patterns.
-
Add optional reason to
@Requiresand@IgnoreIf#1362 -
Add
shared.support to conditional extensions #1359. See Precondition Context for more details. -
Set the owner for condition closures on spec annotations #1357
This allows access to static methods when
@IgnoreIf,@Requiresand@PendingFeatureIfis used on a Specification. -
Update bnd Gradle plugin to 6.0.0 (OSGI) #1377
-
Fix selector ordering issue #1375
-
Fix
@TempDirnot working for@Sharedinherited fields #1373 -
Fix JUnit rule run order #1363
-
Prevent removal of ErrorSpecNode from execution hierarchy #1358
As the ErrorSpecNode does not have children it would get removed when trying to select specific tests methods For example, gradle will report that no test were found, and not report the actual error.
-
Fix double invocation of IRunListener.beforeSpec and IRunListener.afterSpec #1344
-
Fix regression with multi-assignment of method call result #1333
-
Fix Build MethodSource with the correct spec class name #1345
Prior to this fix, all
SpockNodethat use aMethodSourcedid not use the actual test class of the discovered method, and instead used the declaring class. This was problematic for inherited test methods, since they appeared to come from the declaring class instead of the current test class. In addition, the Maven Surefire provider failed to match such methods when executing tests matching a mask (e.g., via-Dtest=*MaskTest). -
Automatically test on CI with JDK 17 (only
-groovy-3.0variant)
Thanks to all the contributors to this release: Marc Philipp, Miles Thomason, BJ Hargrave, Marcin Zajączkowski, Lőrinc Pap, Felipe Pedrosa, Marcin Świerczyński, Benedikt Ritter
2.0 (2021-05-17)
Highlights
-
Spock is now a test engine based on the JUnit Platform
-
Spock now supports Parallel Execution on the spec and feature level, with powerful tools for shared resource access.
-
Support for Groovy 3
-
Data driven tests are now unrolled by default with a more informative naming scheme
-
Data driven tests can now declare a subset of parameters, which are injected by name instead of position.
... and many more, read the full release notes for every detail.
Migrating from 1.x
The Migration Guide 1.x - 2.0 covers the major breaking changes between 1.3 and 2.0
Breaking Changes (from 2.0-M5)
-
Remove
@ResourceLockChildrenagain, as JUnit Platform 5.7.2 makes it obsolete. With the update aREADlock on a parent node, does not force same thread execution on its children. If you are one of the few that have already used@ResourceLockChildren, just replace it with@ResourceLock.
Misc
-
Fix NPE if variable is initialized using a method with the same in features with cleanup blocks or using thrown condition #1266 #1313
-
Fix implicit this conversion after bugfix in Groovy 3.0.8 #1318
-
Fix extension-provided method arguments in fixture methods #1305
-
Update
Jvmhelper to support versions up to 23 (next LTS release)
Thanks to all the contributors (all 2.0 Milestones): Björn Kautler, Marcin Zajączkowski, DQYuan, Marcin Erdmann, Alexander Kriegisch, Jasper Vandemalle, Tom Wieczorek, Josh Soref, Vaidotas Valuckas, Raymond Augé, Roman Tretiak, Camilo Jorquera, Shil Sinha, Ryan Gardner, k3v1n0x90
Special thanks goes to Marc Philipp who helped a lot with the integration of the JUnit Platform.
2.0-M5 (2021-03-23)
Breaking Changes
-
The
ReportLogExtensionvestiges were removed. As this extension was mostly used for an unreleased Spock module, this won’t affect many users. If you are using a Spock Configuration File with areportsection, then you must delete everything from this section except forissueNamePrefixandissueUrlPrefix. These two properties are still supported and used by the@Issueextension.
Misc
-
Add support for injection into
@Sharedfields inspock-springmodule which users can opt-in for by adding@EnableSharedInjectionto the specification. #76
-
Add new
displayNameviaINameableforSpecInfo,FeatureInfo, andIterationInfo. This field can be set via extensions to change the reported name. The existing iterationNameProvidernow also sets thedisplayNameinstead of thename. Modifying thenameinstead ofdisplayNameis now considereddeprecatedfor extensions. #1236 -
Add support for constructor injection for extensions
-
Improve final field handling. Final fields are now transformed similar to shared fields, so that we can still delay the initialization but keep them unmodifiable to user code. #1011
-
Improve parallel extensions to support inheritance #1245
-
Improve PollingConditions
-
Improve some AST transformation code regarding error handling
-
Deprecate
AbstractGlobalExtensionand replace withIGlobalExtension -
Remove unnecessary try-finally construct for assertions
-
Fix ErrorSpecNode throw Exception in
prepareinstead ofexecutethis fixes an issue that interceptors forprepare,before, andaroundwere still executed and any Exception they throw would hide the actual cause. -
Fix #1294 swallowing of unrecoverable Errors
-
Fix #1260 Change InteractionRewriter to keep casting of ListExpressions intact
-
Fix #1282 Make TempDirInterceptor safe for parallel invocation of iterations
-
Fix #1267 Retry extension behavior for unrolled tests
-
Fix #1267 Retry extension behavior for unrolled tests
-
Fix #1229
@TempDirnot working for inherited fields -
Fix #1232 compile error for nested conditions without top-level condition
-
Fix #1256 handling of
isas getter for boolean properties on Mocks -
Fix #1270 handling of
isas getter for boolean properties on GroovyMocks -
Fix
ErrorSpecNodeto re-throwExceptioninprepareinstead ofexecute, this fixes an issue that interceptors forprepare,before, andaroundwere still executed and any Exception they throw would hide the actual cause. -
Fix #1263 ExceptionAdapterExtension to also handle inherited fixture methods
-
Fix #1279 Cast data variables with type coercion to the declared parameter type
Thanks to all the contributors to this release: Marcin Erdmann, Björn Kautler, Alexander Kriegisch, Josh Soref, Vaidotas Valuckas
2.0-M4 (2020-11-01)
-
Added Parallel Execution support
-
Add a way to register
ConfigurationObjectglobally without the need for a global extension. -
Annotations for local extensions can now be defined as
@Repeatableand applied multiple times to the same target. Spock will handle this appropriately and call the extensionsvisitSpecAnnotationsmethod with all annotations. If these methods are not overwritten, they forward to the usualvisitSpecAnnotationmethods once for each annotation. -
@ConfineMetaClassChanges,@Issue,@IgnoreIf,@PendingFeatureIf,@Requires,@See,@Subject,@Use, and@UseModulesare now repeatable annotations -
@Requires,@IgnoreIfand@PendingFeatureIfcan now access instance fields, shared fields and instance methods by using theinstance.qualifier inside the condition closure. -
AbstractAnnotationDrivenExtensionis now deprecated and its logic was moved todefaultmethods ofIAnnotationDrivenExtensionwhich should be implemented directly now instead of extending the abstract class. -
Add
@TempDirbuilt-in extension -
@PendingFeatureand@PendingFeatureIfcan now be used together -
Fix #1158 Fix strange bug with setter/getter handling of mocks in groovy
-
Fix #1216 perform argument coercion for
GroovyMockmethod arguments -
Fix #1169 check skipped state in Node.prepare and do nothing if already skipped
-
Fix #1200 name clashes where variables that are named like method calls destroy the method call
-
Fix #1202 NullPointerException with array initializers
-
Fix #994 don’t treat nested closures in argument constraints as implicit assertions anymore
-
Replace
hamcrest-coredependency byhamcrest
Thanks to all the contributors to this release: Björn Kautler, Marcin Zajączkowski, DQYuan, Tom Wieczorek, Alexander Kriegisch, Jasper Vandemalle
2.0-M3 (2020-06-11)
Breaking Changes
Sputnik Runner removed (an alternative)
In 2.0-M1 the Sputnik runner was removed and the 2.0-M2 release notes explicitly mentioned that enhancements
that extend Sputnik or use it as a delegate like for example the PowerMockRunnerDelegate will not work anymore.
This is not the full truth though, but be aware that the information in this section is just for informational purpose. This is not a solution the Spock maintainers explicitly support or maintain. It is just mentioned as hint for those that have no other choice right now. It is strongly recommended to instead use native solutions or integrations. If those are not available, you might consider asking about proper integration with Spock for a proper long-term solution. As long as this is not available, the work-around described here is at least usable as fallback and mid-term solution as long as the JUnit team decides to maintain this legacy support module.
There is a JUnit 4 runner provided by JUnit 5 called JUnitPlatform that can
run any JUnit platform based tests - like Spock 2+ based tests - in a JUnit 4 environment. This is intended
for situations where an IDE, build tool, CI server, or similar does not yet natively support JUnit platform.
It is provided in the artifact org.junit.platform:junit-platform-runner.
This means, if you make sure your tests are launched with JUnit 4 and you use JUnitPlatform where you before used
Sputnik, all should work out properly. In case of PowerMock this means you annotate your specification with
@RunWith(PowerMockRunner) and @PowerMockRunnerDelegate(JUnitPlatform) and make sure your tests are launched
using JUnit 4.
Removal of JUnit 4 dependency from spock-core
Spock 2.0 from the beginning has leveraged JUnit Platform to execute tests. However, starting with 2.0-M3 junit4.jar is no longer a transitive dependency of spock-core. This might affect people using @Before/@After/… instead of Spock-native setup/cleanup/… fixture methods. To keep it work the spock-junit4 dependency has to be added.
As a side effect of the removal, the order of the fixture methods execution has changed from:
beforeClass, setupSpec, before, setup, cleanup, after, setup, before, cleanup, after, cleanupSpec, afterClassto:
setupSpec, beforeClass, setup, before, cleanup, after, setup, before, cleanup, after, cleanupSpec, afterClasswhich should not be a problem in the majority of cases.
At the same time, using JUnit 4’s annotations is discouraged (and considered deprecated), the same using the other elements of JUnit 4 (as `(Class)Rule`s).
Reduce spock-core direct groovy dependencies
spock-core now only depends on groovy.jar. All other Groovy dependencies have been removed,
this should make dependency management a bit easier.
If you relied on other groovy dependencies transitively, you will need to add them directly.
Upgrade to JUnit 5.6 (and JUnit Platform 1.6)
JUnit Platform 1.6 deprecated methods (from experimental API) in EngineExecutionResults that Spock was using. To keep runtime compatibility with JUnit 5.6 and incoming 5.7 the implementation has been switched to the new methods. As a result, Spock 2.0-M3 cannot work with JUnit 5.5 and lower. The problem might only occur if a project overrides default JUnit Platform version provided by Spock.
New meaning of >> _
The meaning of >> _ has changed from "use the default response" to "return a stubbed value" (Docs).
The original behavior was only ever documented in the Javadocs and was basically the same to just omitting it.
The only use-case was chained responses >> "a" >> _ >> "b",
but even here it is clearer to just use null or { callRealMethod() } explicitly.
With the new behavior, you can have a Mock or Spy return the same value as a Stub would.
subscriber.receive(_) >> _Renamed iterationCount token
The token #iterationCount in unroll patterns was renamed to #iterationIndex.
If you use it somewhere, you have to manually change it to the new name
or the test will fail unless you disabled expression asserting,
then you will get an #Error:iterationCount rendering instead.
No access to data variables in data pipes anymore
It is not possible anymore to access any data variable from a data pipe or anything else but a previous data table column in a data table cell. This access was partly possible, but could easily prematurely drain iterators, access data providers sooner as expected, behaved differently depending on the concrete code construct used. All these points are more confusing than necessary. If you want to calculate a data variable from others, you can always use a derived data variable that has full access to all previous data variables and can also call helper methods for more complex logic.
If you switch your tests that are fully green to use Spock 2.0 and get any MissingPropertyExceptions, you are probably hitting this change, you should then change to a derived data variable there instead of a data pipe.
If you for example had:
where:
a << [1, 2]
b << awhat you want instead is:
where:
a << [1, 2]
b = aAssert unroll expressions by default
The system property spock.assertUnrollExpressions is not supported anymore.
Instead the new default behavior is equal to having this property set to true.
This means tests that were successful but had an #Error: name rendering will now fail.
It can be set back to the old pre Spock 2.0 behaviour by setting
unroll { validateExpressions false } in the Spock configuration file.
For extension developers
-
FeatureInfo#getDataVariables()andFeatureInfo#getParameterNames()used to return the same value, the parameter names, in the order of the method parameters. This can disturb some calculations like method argument determination and so on and is plainly wrong, as some parameters could be injected by extensions like injecting mock objects or test proxies or similar.FeatureInfo#getDataVariables()now only returns the actual data variables and in the order how they are defined in thewhereblock. -
Method arguments in
MethodInfonow have a value ofMethodInfo.MISSING_ARGUMENTif no value was set so far, for example by some extensions or from data variables. If any of these is not replaced by some value, an exception will be thrown at runtime.
Ant support removed
SpecClassFileSelector was removed, which was the only class that required ant.
If you are still using spock with ant, then you can just copy the class from the spock source code into your build.
Misc
-
A new
MutableClockutility class to support time related testing, see docs. -
Defining interactions on property getters within Mock instantiation closures or
withclosures works now without the need to explicitly qualify the property access withit.:Foo foo = Stub { bar >> 'my stubbed property' } -
A sequence of two or more underscores can be used to separate multiple data tables in one
whereblock. -
Type casts in conditions are now properly carried over to properly disambiguate method calls. For more information see issue #1022.
-
Data tables now support any amount of semicolons to separate data table columns as alternative to pipes and double pipes, but cannot be mixed with them in one table:
where: a ; b ;; c 1 ; 2 ;; 3
-
The default unroll pattern changed from the rather generic
#featureName[#iterationIndex]to a more fancy version that lists all data variables and their values additionally to the feature name and iteration index. If you prefer to retain the old behaviour, you can set the settingunroll { defaultPattern '#featureName[#iterationIndex]' }in the Spock configuration file and you will get the same result as previously. -
If neither a parameter to the
@Unrollannotation is given, nor the method name contains a#, now the configuration file settingunroll { defaultPattern }is inspected. If it is set to a non-nullstring, this value is used as unroll pattern. -
IterationInfonow has a property for theiterationIndexand one for a map of data variable names to values. This is typically not interesting for the average user, but might be helpful for authors of Spock extensions. -
constructorArgsnow properly transport type cast information to the constructor selection, for example to disambiguate multiple candidate constructors:Spy(constructorArgs: [null as String, (Pattern) null]) -
Accessing previous data table columns was broken in some cases, now it should work properly, even cross-table and without being disturbed by previous derived data variables.
-
The order of parameters in a data-driven feature does no longer have to be identical to the declaration order in the
whereblock. Data variables are now injected by name. -
Data driven features do no longer have the requirement that either none or all data variables are declared as parameters and that all parameters are also data variables. Now you can either declare none, some, or all data variables as parameters and also have additional method parameters that are no data variables. Those additional parameters must be provided by some Spock extension though. If they are not set at execution time, an exception will be thrown.
-
Condition closures used in
@Requires,@IgnoreIfand@PendingFeatureIfnow also get the context passed as argument, so you can use this, typed asorg.spockframework.runtime.extension.builtin.PreconditionContextto enable IDE support like code completion:@IgnoreIf({ PreconditionContext it -> it.os.windows }) def "I'll run everywhere but on Windows"() { ... } -
Execution with an unsupported Groovy version can be allowed with
-Dspock.iKnowWhatImDoing.disableGroovyVersionCheck=true(#1164) -
Relax maximum allowed Groovy version in snapshot builds (#1108)
-
Upgrade Groovy to 2.5.12 (improved Java 14+ support) and 3.0.4 (fixes #1127)
-
Upgrade JUnit 4 to 4.13 (in
spock-junit4) -
Upgrade Hamcrest to 2.2 (from 1.3 provided previously by
junit4.jar) -
Derived data variables (assignments in
whereblocks) now also support multi-assignment syntax, including ignoring some values with the wildcard expression.(a, b, _, c) = row -
Multi-variable data pipes now also support nesting.
[a, [_, b]] << [ [1, [5, 1]], [2, [5, 2]] ] -
The condition closures for
@IgnoreIf,@Requiresand@PendingFeatureIfcan now access data variables if applied to a data driven feature. This has further implications that are documented in the respective documentation parts and JavaDocs.
-
Data driven features are now unrolled by default.
@Unrollcan still be used to specify a custom naming pattern. A simple@Unrollwithout argument is not needed anymore except when undoing a spec-level@Rollupannotation or if unrolling by default is disabled, so any simple@Unrollannotations can be removed from existing code. You can verify this by looking at the test count which should not have been changed after you removed the simple@Unrollannotations. -
@Rollupcan now be used on feature and spec level to explicitly roll up any feature where the reporting of single iterations is not wanted. -
The setting
unroll { unrollByDefault false }in the Spock configuration file can be set to roll up all features by default if not overwritten by explicit@Unrollannotations and thus reinstate the pre Spock 2.0 behaviour. -
Updated OSGI support with using
bnd(#1154, #1175) -
Fix
@PendingFeaturelogic (#1103) -
Do not strip type information from arguments (#1134)
-
Simplify work-around to get the reference to the current closure (#1131)
-
Set source position for return statement in data provider method (#1116)
-
Add
Spy(T obj, Closure interactions)(#1115) -
Reduce number of Groovy dependencies to just groovy.jar (#1109)
-
Improve
ExceptionUtil.sneakyThrowdeclaration (#1077) -
Print up to 5 last mock invocations for a wrong order error (#1093)
-
Fix
EmptyOrDummyResponsereturning mock instance forObject(#1092) -
Remove unnecessary reflection for Java 8 types in
EmptyOrDummyResponse(#1091) -
Update old Issue annotations to point to migrated github issues (#1003)
-
Test Spock with Java 14 (#1155)
Thanks to all the contributors to this release: Björn Kautler, Marcin Zajączkowski, Raymond Augé, Roman Tretiak, Camilo Jorquera, Shil Sinha
2.0-M2 (2020-02-10)
Groovy-3.0 Support
The main feature of this milestone is support for Groovy 3.
To use Spock in your Groovy 3 project just select the spock-\*-2.0-M2 artifact(s) ending with -groovy-3.0.
|
Note
|
As Groovy 3 is not backward compatible with Groovy 2, there is a layer of abstraction in Spock to allow to build (and use) the project with both Groovy 2 and 3.
As a result, an extra artifact spock-groovy2-compat is (automatically) used in projects with Groovy 2.
It is very important to do not mix the spock-*-2.x-groovy-2.5 artifacts with the groovy-*-3.x artifacts on a classpath.
This may result in weird runtime errors.
|
Breaking Changes
Sputnik Runner removed
Although already in 2.0-M1 it wasn’t explicitly mentioned: All enhancements that either extended Sputnik
or used it as a delegate runner will not work anymore, e.g, PowerMockRunnerDelegate.
Misc
-
Add
@PendingFeatureIfannotation (Docs) -
Fail-fast for invalid
Stubinteractions, added new validation that catches more invalid usage ofStub -
Forbid spying on
Spyinstances, as this doesn’t work anyway and leads to wrong expectations (#1029) -
Update
Jvmhelper utility to include new Java versions, removed pre 8 versions -
Update docs regarding ByteBuddy, cglib, objenesis
-
Provide compatibility to both JUnit 5.5.2 and 5.6.0
Thanks to all the contributors to this release: Marcin Zajączkowski (Groovy 3 support), Björn Kautler, Ryan Gardner
2.0-M1 (2019-12-31)
This is the first milestone release to version 2.0. This means that we have migrated to the new JUnit Platform and all internal tests pass. We have tried to keep the API as compatible as possible and if you’ve only used the public spock API then there is a high possibility that all you have to do is to update the spock version and configure gradle/maven to use the JUnit Platform.
However, this doesn’t mean that the API is finalized yet, the goal for the first milestone was just to get it running on the new platform. The next milestones will focus on improvements like the much requested parallel execution support.
Please try it out and report any new bugs so that we can fix them for the final 2.0 release.
Breaking Changes
New JUnit Platform
Switch from JUnit 4 to the JUnit Platform. See https://junit.org/junit5/docs/current/user-guide/#running-tests-build on how to configure maven and gradle to use the JUnit Platform.
JUnit 4 Rules are not supported by spock-core anymore, however, there is a new spock-junit4
module that provides best effort support to ease migration.
Misc
-
Spock now requires at least Java 8
-
All data-driven test iterations are always reported (unrolled), while
@Unrollis not necessary anymore it can still be used to define the name template -
@Retry.Mode.FEATUREdidn’t work anymore and has been removed -
spock-reportmodule has been removed, it was never officially released -
The
SpockReportingExtensionhas been disabled until we can integrate it with JUnitPlatform -
Removed testing for
spring-2.xas it is incompatible -
Fix some Javadocs
Special thanks goes to Marc Philipp who helped a lot with the integration of the JUnit Platform.
Thanks to all the contributors to this release: Marcin Zajączkowski, k3v1n0x90
1.3 (2019-03-05)
No functional changes
1.3-RC1 (2019-01-22)
The theme for this release is to increase the information that is provided when an assertion failed.
Potential breaking changes
code argument constraints are treated as implicit assertions
Before this release the code argument constrains worked by returning a boolean result.
This was fine if you just wanted to do a simple comparison, but it breaks down if you
need to do 5 comparisons. Users also often assumed that it worked like the assertions in
then blocks and didn’t add && to chain multiple assertions together, so their constraint
ignored all before the next line.
1 * mock.foo( { it.size() > 1
it[0].length == 2 })This would only use the length comparison, to make it work you had to add &&.
Another problem arises by having more than one comparison inside the constraints,
you don’t know which of the 5 comparisons failed. If you just expected one method
call you could use an explicit assert as a workaround, but since it immediately
breaks, you can’t use it if you want to have multiple different calls to the same
mock.
With 1.3 the above code will actually work as intended, and even more important it will give actual feedback what didn’t match.
So what can break?
If you used the code argument constraint as a way of capturing the argument value, then this will most likely not work anymore, since assignments to already declared variables are forbidden in implicit assertion block. If you still need access to the argument, you can use the response generator closure instead.
def extern = null
1 * mock.foo( { extern = it; it.size() > 0 }) // old
1 * mock.foo( { it.size() > 0 }) >> { extern = it[0] } // newThe added benefit of this changes is, that it clearly differentiates the condition from the capture.
Another consequence of the change is, that the empty {} assertion block will now pass
instead of fail, since no assertion error is being treated as passing, while it required
a true result beforehand.
It is advised, that if you have multiple conditions joined by &&, that you remove
it to get individual assertions reports instead of a large joined block.
assertions with explicit messages now include power assertions output.
def a = 1
def b = 2
assert a == b : "Additional message"a == b Additional message
a == b | | | 1 | 2 false Additional message
If you relied on this behavior to hide some output, or to prevent a stack overflow due to a self referencing data structure, then you need to move the condition into a separate method that just returns the boolean result.
What’s New In This release
-
Add implicit assertions for CodeArgument constraints (#956)
-
Add power assertion output to asserts with explicit message (#928)
-
Add support for mixed named and positional arguments in mocks (#919)
-
Add NamedParam support for groovy-2.5 with backport to 2.4 (#921)
-
Add special rendering for Set comparisons (#925)
-
Add identity hash code to type hints in comparison failures if they are identical
-
Fix erroneous regex where an optional colon was defined instead of a non-capturing group (#931)
-
Improve CodeArgumentConstraint by supporting assertions (#918)
-
Improve IDE type inference in MockingApi (#920)
-
Improve reporting of TooFewInvocationsError (#912)
-
Improve render class loader for classes in comparison failures (#932)
-
Improve record class literal values to display FQCN in comparison failures (#935)
-
Improve filter Java 9+ reflection stack frames
-
Improve show stacktrace of throwables in comparison failure result
-
Improve use canonical class name in comparison failure results if present
-
Improve render otherwise irrelevant expressions if they get a type hint in comparison failure (#936)
-
Fix do not convert implicit "this" expression like when calling the constructor of a non-static inner class (#930)
-
Fix class expression recording when there are comments with dots in the same line (#937)
Thanks to all the contributors to this release: Björn Kautler, Marc Philipp, Marcin Zajączkowski, Martin Vseticka, Michael Kutz, Kacper Bublik
1.2 (2018-09-23)
Breaking Changes: Spock 1.2 drops support for Java 6, Groovy 2.0 and Groovy 2.3
What’s New In This release
-
Add Groovy 2.5.0 Variant for better Java 10+ Support
-
Add
@SpringBeanand@SpringSpyinspired by@MockBean, Also add@StubBeans(Docs) -
Add
@UnwrapAopProxyto make automatically unwrap SpringAopProxies -
Add
@AutoAttachextension (Docs) -
Add
@Retryextension (Docs) -
Add flag to UnrollNameProvider to assert unroll expressions (set the system property
spock.assertUnrollExpressionstotrue) (#767) -
Add automatic module name descriptors for Java 9
-
Add configurable
conditionto@Retryextension to allow for customizing when retries should be attempted (Docs) -
Improve
@PendingFeatureto now have an optionalreasonattribute (#907) -
Improve
@Retryto be declarable on a spec class which will apply it to all feature methods in that class and subclasses (Docs) -
Improve StepwiseExtension mark only subsequent features as skipped in case of failure (#893)
-
Improve in assertions Spock now uses
DefaultGroovyMethods.dumpinstead oftoStringif a class doesn’t override the defaultObject.toString. -
Improve
verifyAllcan now also have a target same aswith -
Improve static type hints for
verifyAllandwith -
Improve reporting of exceptions during cleanup, they are now properly reported as suppressed exceptions instead of hiding the real exception
-
Improve default responses for stubs, Java 8 types like
OptionalandStreamsnow return empty,CompletableFuturecompletes withnullresult -
Improve support for builder pattern, stubs now return themselves if the return type matches the type of the stub
-
Improve tapestry support with by supporting
@ImportModule -
Improve
constructorArgsfor spies can now accept a map directly without the need to wrap it in a list -
Improve Guice Module now automatically attaches detached mocks
-
Improve unmatched mock messages by using
dumpinstead ofinspectfor classes which don’t provide a customtoString -
Improve spying on concrete instances to enable partial mocking
-
Fix use String renderer for Class instances (#909)
-
Fix mark new Spring extensions as @Beta (#890)
-
Fix exclude groovy-groovysh from compile dependencies (#882)
-
Fix
Retry.Mode.FEATUREandRetry.Mode.SETUP_FEATURE_CLEANUPto make a test pass if a retry was successful. -
Fix issue with
@SpringBeanmocks throwingInvocationTargetExceptioninstead of actual declared exceptions (#878, #887) -
Fix void methods with implicit targets failing in
withandverifyAll(#886) -
Fix SpockAssertionErrors and its subclasses now are properly
Serializable -
Fix Spring injection of JUnit Rules, due to the changes in 1.1 the rules where initialized before Spring could inject them, this has been fixed by performing the injection earlier in the process
-
Fix SpringMockTestExecutionListener initializes lazy beans
-
Fix OSGi Import-Package header
-
Fix re-declare recorder variables (#783), this caused annotations such as
@Slf4jto break Specifications -
Fix MissingFieldException in DiffedObjectAsBeanRenderer
-
Fix problems with nested
withandverifyAllmethod calls -
Fix assertion of mock invocation order with nested invocations (#475)
-
Fix ignore inferred type for Spies on existing instance
-
General dependency update
Thanks to all the contributors to this release: Marc Philipp, Rob Elliot, jochenberger, Jan Papenbrock, Paul King, Marcin Zajączkowski, mrb-twx, Alexander Kazakov, Serban Iordache, Xavier Fournet, timothy-long, John Osberg, AlexElin, Benjamin Muschko, Andreas Neumann, geoand, Burk Hufnagel, signalw, Martin Vseticka, Tilman Ginzel
1.2-RC3 (2018-09-16)
What’s New In This release
-
Add support for Java 11+ (#895, #902, #903)
-
Improve
@PendingFeatureto now have an optionalreasonattribute (#907) -
Fix use String renderer for Class instances (#909)
-
Fix mark new Spring extensions as @Beta (#890)
-
Fix exclude groovy-groovysh from compile dependencies (#882)
Thanks to all the contributors to this release: Marc Philipp, Marcin Zajączkowski, signalw
1.2-RC2 (2018-09-04)
What’s New In This release
-
Add configurable
conditionto@Retryextension to allow for customizing when retries should be attempted (Docs) -
Fix
Retry.Mode.FEATUREandRetry.Mode.SETUP_FEATURE_CLEANUPto make a test pass if a retry was successful. -
Improve
@Retryto be declarable on a spec class which will apply it to all feature methods in that class and subclasses (Docs) -
Improve StepwiseExtension mark only subsequent features as skipped in case of failure (#893)
-
Fix issue with
@SpringBeanmocks throwingInvocationTargetExceptioninstead of actual declared exceptions (#878, #887) -
Fix void methods with implicit targets failing in
withandverifyAll(#886)
Thanks to all the contributors to this release: Marc Philipp, Tilman Ginzel, Marcin Zajączkowski, Martin Vseticka
1.2-RC1 (2018-08-14)
Breaking Changes: Spock 1.2 drops support for Java 6, Groovy 2.0 and Groovy 2.3
What’s New In This release
-
Add Groovy 2.5.0 Variant for better Java 10 Support
-
Add @SpringBean and @SpringSpy inspired by @MockBean, Also add @StubBeans
-
Add @UnwrapAopProxy to make automatically unwrap SpringAopProxies
-
Add flag to UnrollNameProvider to assert unroll expressions (set the system property
spock.assertUnrollExpressionstotrue) #767 -
Add automatic module name descriptors for Java 9
-
Add
@AutoAttachextension (Docs) -
Add
@Retryextension (Docs) -
Fix SpockAssertionErrors and its subclasses now are properly
Serializable -
Fix Spring injection of JUnit Rules, due to the changes in 1.1 the rules where initialized before Spring could inject them, this has been fixed by performing the injection earlier in the process
-
Fix SpringMockTestExecutionListener initializes lazy beans
-
Fix OSGi Import-Package header
-
Fix re-declare recorder variables (#783), this caused annotations such as
@Slf4jto break Specifications -
Fix MissingFieldException in DiffedObjectAsBeanRenderer
-
Fix problems with nested
withandverifyAllmethod calls -
Fix assertion of mock invocation order with nested invocations (#475)
-
Fix ignore inferred type for Spies on existing instance
-
Improve in assertions Spock now uses
DefaultGroovyMethods.dumpinstead oftoStringif a class doesn’t override the defaultObject.toString. -
Improve
verifyAllcan now also have a target same aswith -
Improve static type hints for
verifyAllandwith -
Improve reporting of exceptions during cleanup, they are now properly reported as suppressed exceptions instead of hiding the real exception
-
Improve default responses for stubs, Java 8 types like
OptionalandStreamsnow return empty,CompletableFuturecompletes withnullresult -
Improve support for builder pattern, stubs now return themselves if the return type matches the type of the stub
-
Improve tapestry support with by supporting
@ImportModule -
Improve
constructorArgsfor spies can now accept a map directly without the need to wrap it in a list -
Improve Guice Module now automatically attaches detached mocks
-
Improve unmatched mock messages by using
dumpinstead ofinspectfor classes which don’t provide a customtoString -
Improve spying on concrete instances to enable partial mocking
-
General dependency update
Thanks to all the contributors to this release: Rob Elliot, jochenberger, Jan Papenbrock, Paul King, Marcin Zajączkowski, mrb-twx, Alexander Kazakov, Serban Iordache, Xavier Fournet, timothy-long, John Osberg, AlexElin, Benjamin Muschko, Andreas Neumann, geoand, Burk Hufnagel
Known Issues
-
Groovy 2.4.10 introduced a bug that interfered with the way
verifyAllworks, it has been fixed in 2.4.12
1.1 (2017-05-01)
What’s New In This release
-
Update docs to include info/examples for Spying instantiated objects
-
Fix integer overflow that could occur when the OutOfMemoryError protection while comparing huge strings kicked in
-
Improve rendering for OutOfMemoryError protection
1.1-rc-4 (2017-03-28)
This should be the last rc for 1.1
What’s New In This release
-
15 merged pull requests
-
Spies can now be created with an already existing target
-
Fix for scoped Spring Beans
-
Fix incompatibility with Spring 2/3 that was introduced in 1.1-rc-1
-
Fix groovy compatibility
-
Fix ByteBuddy compatibility
-
Fix OutOfMemoryError when comparing huge strings
-
Improve default response for
java.util.Optional<T>, will now return empty optional -
Improve detection of Spring Boot tests
-
Improve documentation for global extensions
Thanks to all the contributors to this release: Taylor Wicksell, Rafael Winterhalter, Marcin Zajączkowski, Eduardo Grajeda, Paul King, Andrii, Björn Kautler, Libor Rysavy
Known issues with groovy 2.4.10 which breaks a smoke test, but should have little impact on normal use (#709).
1.1-rc-3 (released 2016-10-17)
Adds compatibility with ByteBuddy as an alternative to cglib for generating mocks and stubs for classes.
1.1-rc-2 (released 2016-08-22)
1.1 should be here soon but in the meantime there’s a new release candidate.
What’s New In This release
-
Support for the new test annotations in Spring Boot 1.4.
-
Fixed the integration of JUnit method rules which now correctly happen "outside" the
setup/cleanupmethods.
Thanks to all the contributors to this release: Jochen Berger, Leonard Brünings, Mariusz Gilewicz, Tomasz Juchniewicz, Gamal Mateo, Tobias Schulte, Florian Wilhelm, Kevin Wittek
1.1-rc-1 (released 2016-06-30)
A number of excellent pull requests have been integrated into the 1.1 stream. Currently some features are incubating. We encourage users to try out these new features and provide feedback so we can finalize the content for a 1.1 release.
What’s New In This release
-
44 merged pull requests
-
The
verifyAllmethod can be used to assert multiple boolean expressions without short-circuiting those after a failure. For example:
then:
verifyAll {
a == b
b == c
}
-
Detached mocks via the
DetachedMockFactoryandSpockMockFactoryBeanclasses see the Spring Module Docs. -
Cells in a data table can refer to the current value for a column to the left.
-
Spycan be used to create partial mocks for Java 8 interfaces withdefaultmethods just as it can for abstract classes. -
Improved power assert output when an exception occurs evaluating an assertion.
-
A new
@PendingFeatureannotation to distinguish incomplete functionality from features with@Ignore.
Special thanks to all the contributors to this release: Dmitry Andreychuk, Aseem Bansal, Daniel Bechler, Fedor Bobin, Leonard Brünings, Leonard Daume, Marcin Erdmann, Jarl Friis, Søren Berg Glasius, Serban Iordache, Michal Kordas, Pap Lőrinc, Vlad Muresan, Etienne Neveu, Glyn Normington, David Norton, Magnus Palmér, Gus Power, Oliver Reissig, Kevin Wittek and Marcin Zajączkowski
1.0 (released 2015-03-02)
1.0 has arrived! Finally (and some years late) the version number communicates what Spock users have known for ages - that Spock isn’t only useful and fun, but also reliable, mature, and here to stay. So please, go out and tell everyone who hasn’t been assimilated that now is the time to join the party!
A special thanks goes to all our tireless speakers and supporters, only a few of which are listed here: Andres Almiray, Cédric Champeau, David Dawson, Rob Fletcher, Sean Gilligan, Ken Kousen, Guillaume Laforge, NFJS Tour, Graeme Rocher, Baruch Sadogursky, Odin Hole Standal, Howard M. Lewis Ship, Ken Sipe, Venkat Subramaniam, Russel Winder.
What’s New In This Release
-
17 contributors, 21 resolved issues, 18 merged pull requests, some ongoing work. No ground-breaking new features, but significant improvements and fixes across the board.
-
Minimum runtime requirements raised to JRE 1.6 and Groovy 2.0.
-
Improved and restyled reference documentation at https://docs.spockframework.org. Generated with Asciidoctor (what else?).
-
Maven plugin removed. Just let Maven Surefire run your Spock specs like your JUnit tests (see spock-example project).
-
Official support for Java 1.8, Groovy 2.3 and Groovy 2.4. Make sure to pick the
groovy-2.0binaries for Groovy 2.0/2.1/2.2,groovy-2.3binaries for Groovy 2.3, andgroovy-2.4binaries for Groovy 2.4 and higher. -
Improved infrastructure to allow for easier community involvement: Switch to GitHub issue tracker, Windows and Linux CI builds, pull requests automatically tested, all development on
masterbranch (bye-byegroovy-x.ybranches!).
Other News
-
Follow our new Twitter account
-
Try these new third-party extensions
-
Check out the upcoming Java Testing with Spock book from Manning
What’s Up Next?
With a revamped build/release process and a reforming core team, we hope to release much more frequently from now on. Another big focus will be to better involve the community and their valuable contributions. Last but not least, we are finally shooting for a professional logo and website. Stay tuned for announcements!
Test Long And Prosper,
The Spock Team
Contributors
17 awesome people contributed to this release:
Resolved Issues
21 burning issues were fixed:
-
Closure used as data value in where-block can’t be called with method syntax
-
Reflect subsequent filtering/sorting in a spec’s JUnit description
-
Data values in where-block are not resolved in nested closures
-
spock-maven:0.7-groovy-2.0 has an invalid descriptor (and a workaround for this)
-
Provide a Specification.with() overload that states the expected target type
-
spock-tapestry should support @javax.inject.Inject and @InjectService
Merged Pull Requests
18 hand-crafted pull requests were merged or cherry-picked:
-
Minor documentation corrections: spelling, code examples. README.md corr…
-
added manifest to core.gradle to allow spock core to work in OSGi land
-
Closure used as data value in where-block can’t be called with method syntax
-
Added docs for Stepwise, Timeout, Use, ConfineMetaClassChanges, AutoClea…
-
Add groovy console support for the specs project, to ease debugging of the AST.
-
Update spock-report/src/test/groovy/org/spockframework/report/sample/Fig…
-
spock-tapestry: added support for @InjectService, @javax.inject.Inject
-
Support overriding Junit After*/Before* methods in the derived class(
New Third Party Extensions
These awesome extensions have been published or updated:
Ongoing Work
These great features didn’t make it into this release (but hopefully the next!):
0.7 (released 2012-10-08)
Snapshot Repository Moved
Spock snapshots are now available from https://oss.sonatype.org/content/repositories/snapshots/org/spockframework/.
New Reference Documentation
The new Spock reference documentation is available at https://docs.spockframework.org. It will gradually replace the documentation at https://wiki.spockframework.org. Each Spock version is documented separately (e.g. https://docs.spockframework.org/en/spock-0.7-groovy-1.8). Documentation for the latest Spock snapshot is at https://docs.spockframework.org/en/latest. As of Spock 0.7, the chapters on Data Driven Testing and Interaction Based Testing are complete.
Improved Mocking Failure Message for TooManyInvocationsError
The diagnostic message accompanying a TooManyInvocationsError has been greatly improved.
Here is an example:
Too many invocations for:
3 * person.sing(_) (4 invocations)
Matching invocations (ordered by last occurrence):
2 * person.sing("do") <-- this triggered the error
1 * person.sing("re")
1 * person.sing("mi")
Improved Mocking Failure Message for TooFewInvocationsError
The diagnostic message accompanying a TooFewInvocationsError has been greatly improved.
Here is an example:
Too few invocations for:
1 * person.sing("fa") (0 invocations)
Unmatched invocations (ordered by similarity):
1 * person.sing("re")
1 * person.say("fa")
1 * person2.shout("mi")
Stubs
Besides mocks, Spock now has explicit support for stubs:
def person = Stub(Person)A stub is a restricted form of mock object that responds to invocations without ever demanding them. Other than not having a cardinality, a stub’s interactions look just like a mock’s interactions. Using a stub over a mock is an effective way to communicate its role to readers of the specification.
Spies
Besides mocks, Spock now has support for spies:
def person = Spy(Person, constructorArgs: ["Fred"])A spy sits atop a real object, in this example an instance of class Person. All invocations on the spy
that don’t match an interaction are delegated to that object. This allows to listen in on and selectively
change the behavior of the real object. Furthermore, spies can be used as partial mocks.
Declaring Interactions at Mock Creation Time
Interactions can now be declared at mock creation time:
def person = Mock(Person) {
sing() >> "tra-la-la"
3 * eat()
}This feature is particularly attractive for Stubs.
Groovy Mocks
Spock now offers specialized mock objects for spec’ing Groovy code:
def mock = GroovyMock(Person)
def stub = GroovyStub(Person)
def spy = GroovySpy(Person)A Groovy mock automatically implements groovy.lang.GroovyObject. It allows stubbing and mocking
of dynamic methods just like for statically declared methods. When a Groovy mock is called from Java
rather than Groovy code, it behaves like a regular mock.
Global Mocks
A Groovy mock can be made global:
GroovySpy(Person, global: true)A global mock can only be created for a class type. It effectively replaces all instances of that type and makes them
amenable to stubbing and mocking. (You may know this behavior from Groovy’s MockFor and StubFor facilities.)
Furthermore, a global mock allows mocking of the type’s constructors and static methods.
Grouping Conditions with Same Target Object
Inspired from Groovy’s Object.with method, the Specification.with method allows to group conditions
involving the same target object:
def person = new Person(name: "Fred", age: 33, sex: "male")
expect:
with(person) {
name == "Fred"
age == 33
sex == "male"
}Grouping Interactions with Same Target Object
The with method can also be used for grouping interactions:
def service = Mock(Service)
app.service = service
when:
app.run()
then:
with(service) {
1 * start()
1 * act()
1 * stop()
}Polling Conditions
spock.util.concurrent.PollingConditions joins AsyncConditions and BlockingVariable(s) as another utility for
testing asynchronous code:
def person = new Person(name: "Fred", age: 22)
def conditions = new PollingConditions(timeout: 10)
when:
Thread.start {
sleep(1000)
person.age = 42
sleep(5000)
person.name = "Barney"
}
then:
conditions.within(2) {
assert person.age == 42
}
conditions.eventually {
assert person.name == "Barney"
}Experimental DSL Support for Eclipse
Spock now ships with a DSL descriptor that lets Groovy Eclipse better understand certain parts of Spock’s DSL. The descriptor is automatically detected and activated by the IDE. Here is an example:
// currently need to type variable for the following to work
Person person = new Person(name: "Fred", age: 42)
expect:
with(person) {
name == "Fred" // editor understands and auto-completes 'name'
age == 42 // editor understands and auto-completes 'age'
}Another example:
def person = Stub(Person) {
getName() >> "Fred" // editor understands and auto-completes 'getName()'
getAge() >> 42 // editor understands and auto-completes 'getAge()'
}DSL support is activated for Groovy Eclipse 2.7.1 and higher. If necessary, it can be deactivated in the Groovy Eclipse preferences.
Experimental DSL Support for IntelliJ IDEA
Spock now ships with a DSL descriptor that lets Intellij IDEA better understand certain parts of Spock’s DSL. The descriptor is automatically detected and activated by the IDE. Here is an example:
def person = new Person(name: "Fred", age: 42)
expect:
with(person) {
name == "Fred" // editor understands and auto-completes 'name'
age == 42 // editor understands and auto-completes 'age'
}Another example:
def person = Stub(Person) {
getName() >> "Fred" // editor understands and auto-completes 'getName()'
getAge() >> 42 // editor understands and auto-completes 'getAge()'
}DSL support is activated for IntelliJ IDEA 11.1 and higher.
Splitting up Class Specification
Parts of class spock.lang.Specification were pulled up into two new super classes: spock.lang.MockingApi
now contains all mocking-related methods, and org.spockframework.lang.SpecInternals contains internal methods
which aren’t meant to be used directly.
Improved Failure Messages for notThrown and noExceptionThrown
Instead of just passing through exceptions, Specification.notThrown and Specification.noExceptionThrown
now fail with messages like:
Expected no exception to be thrown, but got 'java.io.FileNotFoundException' Caused by: java.io.FileNotFoundException: ...
HamcrestSupport.expect
Class spock.util.matcher.HamcrestSupport has a new expect method that makes
Hamcrest assertions read better in then-blocks:
when:
def x = computeValue()
then:
expect x, closeTo(42, 0.01)@Beta
Recently introduced classes and methods may be annotated with @Beta, as a sign that they may still undergo incompatible
changes. This gives us a chance to incorporate valuable feedback from our users. (Yes, we need your feedback!) Typically,
a @Beta annotation is removed within one or two releases.
Fixed Issues
See the issue tracker for a list of fixed issues.
0.6 (released 2012-05-02)
Mocking Improvements
The mocking framework now provides better diagnostic messages in some cases.
Multiple result declarations can be chained. The following causes method bar to throw an IOException when first called,
return the numbers one, two, and three on the next calls, and throw a RuntimeException for all subsequent calls:
foo.bar() >> { throw new IOException() } >>> [1, 2, 3] >> { throw new RuntimeException() }It’s now possible to match any argument list (including the empty list) with foo.bar(*_).
Method arguments can now be constrained with Hamcrest matchers:
import static spock.util.matcher.HamcrestMatchers.closeTo
...
1 * foo.bar(closeTo(42, 0.001))Extended JUnit Rules Support
In addition to rules implementing org.junit.rules.MethodRule (which has been deprecated in JUnit 4.9), Spock now also
supports rules implementing the new org.junit.rules.TestRule interface. Also supported is the new @ClassRule
annotation. Rule declarations are now verified and can leave off the initialization part. I that case Spock will
automatically initialize the rule by calling the default constructor. The @TestName rule, and rules in general, now
honor the @Unroll annotation and any defined naming pattern.
See Issue 240 for a known limitation with Spock’s TestRule support.
Condition Rendering Improvements
When two objects are compared with the == operator, they are unequal, but their string representations are the same,
Spock will now print the objects' types:
enteredNumber == 42 | | | false 42 (java.lang.String)
JUnit Fixture Annotations
Fixture methods can now be declared with JUnit’s @Before, @After, @BeforeClass, and @AfterClass annotations,
as an addition or alternative to Spock’s own fixture methods. This was particularly needed for Grails 2.0 support.
Tapestry 5.3 Support
Thanks to a contribution from Howard Lewis Ship, the Tapestry module is now compatible with Tapestry 5.3. Older 5.x versions are still supported.
IBM JDK Support
Spock now runs fine on IBM JDKs, working around a bug in the IBM JDK’s verifier.
Improved JUnit Compatibility
org.junit.internal.AssumptionViolatedException is now recognized and handled as known from JUnit. @Unrolled methods
no longer cause "yellow" nodes in IDEs.
Improved @Unroll
The @Unroll naming pattern can now be provided in the method name, instead of as an argument to the annotation:
@Unroll
def "maximum of #a and #b is #c"() {
expect:
Math.max(a, b) == c
where:
a | b | c
1 | 2 | 2
}The naming pattern now supports property access and zero-arg method calls:
@Unroll
def "#person.name.toUpperCase() is #person.age years old"() { ... }The @Unroll annotation can now be applied to a spec class. In this case, all data-driven feature methods in the class
will be unrolled.
Improved @Timeout
The @Timeout annotation can now be applied to a spec class. In this case, the timeout applies to all feature methods
(individually) that aren’t already annotated with @Timeout. Timed methods are now executed on the regular test
framework thread. This can be important for tests that rely on thread-local state (like Grails integration tests).
Also the interruption behavior has been improved, to increase the chance that a timeout can be enforced.
The failure exception that is thrown when a timeout occurs now contains the stacktrace of test execution, allowing you to see where the test was “stuck” or how far it got in the allocated time.
Improved Data Table Syntax
Table cells can now be separated with double pipes. This can be used to visually set apart expected outputs from provided inputs:
...
where:
a | b || sum
1 | 2 || 3
3 | 1 || 4Groovy 1.8/2.0 Support
Spock 0.6 ships in three variants for Groovy 1.7, 1.8, and 2.0. Make sure to pick the right version - for example, for Groovy 1.8 you need to use spock-core-0.6-groovy-1.8 (likewise for all other modules). The Groovy 2.0 variant is based on Groovy 2.0-beta-3-SNAPSHOT and only available from https://m2repo.spockframework.org. The Groovy 1.7 and 1.8 variants are also available from Maven Central. The next version of Spock will no longer support Groovy 1.7.
Grails 2.0 Support
Spock’s Grails plugin was split off into a separate project and now lives at https://github.spockframework.org/spock-grails. The plugin supports both Grails 1.3 and 2.0.
The Spock Grails plugin supports all of the new Grails 2.0 test mixins, effectively deprecating the existing unit testing classes (e.g. UnitSpec). For integration testing, IntegrationSpec must still be used.
IntelliJ IDEA Integration
The folks from JetBrains have added a few handy features around data tables. Data tables will now be layed out automatically when reformatting code. Data variables are no longer shown as "unknown" and have their types inferred from the values in the table (!).
GitHub Repository
All source code has moved to https://github.spockframework.org/. The Grails Spock plugin, Spock Example project, and Spock Web Console now have their own GitHub projects. Also available are slides and code for various Spock presentations (such as this one).
Gradle Build
Spock is now exclusively built with Gradle. Building Spock yourself is as easy as cloning the
Github repo and executing gradlew build. No build tool installation is
required; the only prerequisite for building Spock is a JDK installation (1.5 or higher).
Fixed Issues
See the issue tracker for a list of fixed issues.
Migration Guide
This page explains incompatible changes between successive versions and provides suggestions on how to deal with them.
2.0
|
Note
|
This section only touches on the breaking changes, see the Release Notes for a full list of changes and new features. |
Spock 2.0 aims to be as compatible as possible for existing code bases, while making the necessary changes to stay a modern test framework.
The biggest change is the switch from being a JUnit 4 Runner to a full-fledged JUnit Platform TestEngine.
That means, that you’ll have to configure your build to use the JUnit Platform to execute tests.
See the JUnit Platform Guide on how to configure your build to use the JUnit Platform.
JUnit 4 support
Support for JUnit 4 has been removed from spock-core, you can use the new spock-junit4 module if you still need JUnit 4 features, such as @Rule.
You can replace the TemporaryFolder rule with the new built-in @TempDir extension.
Spock 2.0 also removed the Sputnik runner, so if you have used PowerMockRunnerDelegate or other things that relied on the runner, you’ll have to find other solutions.
Take a look at Third-Party-Extensions for solutions.
Reduce spock-core direct groovy dependencies
spock-core now only depends on groovy.jar. All other Groovy dependencies have been removed,
this should make dependency management a bit easier.
If you relied on other groovy dependencies transitively, you will need to add them directly.
Unroll changes
-
Data driven features are now unrolled by default.
@Unrollcan still be used to specify a custom naming pattern. A simple@Unrollwithout argument is not needed anymore except when undoing a spec-level@Rollupannotation or if unrolling by default is disabled, so any simple@Unrollannotations can be removed from existing code. You can verify this by looking at the test count which should not have been changed after you removed the simple@Unrollannotations. -
@Rollupcan now be used on feature and spec level to explicitly roll up any feature where the reporting of single iterations is not wanted. -
The setting
unroll { unrollByDefault false }in the Spock configuration file can be set to roll up all features by default if not overwritten by explicit@Unrollannotations and thus reinstate the pre Spock 2.0 behaviour.
-
The default unroll pattern changed from the rather generic
#featureName[#iterationIndex]to a more fancy version that lists all data variables and their values additionally to the feature name and iteration index. If you prefer to retain the old behaviour, you can set the settingunroll { defaultPattern '#featureName[#iterationIndex]' }in the Spock configuration file and you will get the same result as previously.
Assert unroll expressions by default
The system property spock.assertUnrollExpressions is not supported anymore.
Instead the new default behavior is equal to having this property set to true.
This means tests that were successful but had an #Error: name rendering will now fail.
It can be set back to the old pre Spock 2.0 behaviour by setting
unroll { validateExpressions false } in the Spock configuration file.
Renamed iterationCount token
The token #iterationCount in unroll patterns was renamed to #iterationIndex.
If you use it somewhere, you have to manually change it to the new name
or the test will fail unless you disabled expression asserting,
then you will get an #Error:iterationCount rendering instead.
New meaning of >> _
The meaning of >> _ has changed from "use the default response" to "return a stubbed value" (Docs).
The original behavior was only ever documented in the Javadocs and was basically the same to just omitting it.
The only use-case was chained responses >> "a" >> _ >> "b",
but even here it is clearer to just use null or { callRealMethod() } explicitly.
With the new behavior, you can have a Mock or Spy return the same value as a Stub would.
No access to data variables in data pipes anymore
It is not possible anymore to access any data variable from a data pipe or anything else but a previous data table column in a data table cell. This access was partly possible, but could easily prematurely drain iterators, access data providers sooner as expected, behaved differently depending on the concrete code construct used. All these points are more confusing than necessary. If you want to calculate a data variable from others, you can always use a derived data variable that has full access to all previous data variables and can also call helper methods for more complex logic.
If you switch your tests that are fully green to use Spock 2.0 and get any MissingPropertyExceptions, you are probably hitting this change, you should then change to a derived data variable there instead of a data pipe.
If you for example had:
where:
a << [1, 2]
b << awhat you want instead is:
where:
a << [1, 2]
b = aAnt support removed
SpecClassFileSelector was removed, which was the only class that required ant.
If you are still using spock with ant, then you can just copy the class from the spock source code into your build.
Other Breaking changes
-
Add new
displayNameviaINameableforSpecInfo,FeatureInfo, andIterationInfo. This field can be set via extensions to change the reported name. The existing iterationNameProvidernow also sets thedisplayNameinstead of thename. Modifying thenameinstead ofdisplayNameis now considereddeprecatedfor extensions. #1236 -
Spock now requires at least Java 8
-
@Retry.Mode.FEATUREdidn’t work anymore and has been removed -
spock-reportmodule has been removed, it was never officially released :leveloffset: -1 -
The
ReportLogExtensionvestiges were removed. As this extension was mostly used for an unreleased Spock module, this won’t affect many users. If you are using a Spock Configuration File with areportsection, then you must delete everything from this section except forissueNamePrefixandissueUrlPrefix. These two properties are still supported and used by the@Issueextension.
1.0
Specs, Spec base classes and third-party extensions may have be recompiled in order to work with Spock 1.0.
JRE 1.5 and Groovy versions below 2.0 are no longer supported.
Make sure to pick the right binaries for your Groovy version of choice: groovy-2.0 for Groovy 2.0/2.1/2.2,
groovy-2.3 for Groovy 2.3, and groovy-2.4 for Groovy 2.4 and higher. Spock won’t let you run with a "wrong" version.
No known source incompatible changes.
0.7
Client code must be recompiled in order to work with Spock 0.7. This includes third-party Spock extensions and base classes.
No known source incompatible changes.
0.6
Class initialization order
|
Note
|
This only affects cases where one specification class inherits from another one. |
Given these specifications:
class Base extends Specification {
def base1 = "base1"
def base2
def setup() { base2 = "base2" }
}
class Derived extends Base {
def derived1 = "derived1"
def derived2
def setup() { derived2 = "derived2" }
}In 0.5, above assignments happened in the order base1, base2, derived1, derived2. In other words, field
initializers were executed right before the setup method in the same class. In 0.6, assignments happen in the order
base1, derived1, base2, derived2. This is a more conventional order that solves a few problems that users
faced with the previous behavior, and also allows us to support JUnit’s new TestRule. As a result of this change,
the following will no longer work:
class Base extends Specification {
def base
def setup() { base = "base" }
}
class Derived extends Base {
def derived = base + "derived" // base is not yet set
}To overcome this problem, you can either use a field initializer for base, or move the assignment of derived into
a setup method.
@Unroll naming pattern syntax
|
Note
|
This is not a change from 0.5, but a change compared to 0.6-SNAPSHOT. |
|
Note
|
This only affects the Groovy 1.8 and 2.0 variants. |
In 0.5, the naming pattern was string based:
@Unroll("maximum of #a and #b is #c")
def "maximum of two numbers"() {
expect:
Math.max(a, b) == c
where:
a | b | c
1 | 2 | 2
}In 0.6-SNAPSHOT, this was changed to a closure returning a GString:
@Unroll({"maximum of $a and $b is $c"})
def "maximum of two numbers"() { ... }For various reasons, the new syntax didn’t work out as we had hoped, and eventually we decided to go back to the string
based syntax. See Improved @Unroll for recent improvements to that syntax.
Hamcrest matcher syntax
|
Note
|
This only affects users moving from the Groovy 1.7 to the 1.8 or 2.0 variant. |
Spock offers a very neat syntax for using Hamcrest matchers:
import static spock.util.matcher.HamcrestMatchers.closeTo
...
expect:
answer closeTo(42, 0.001)Due to changes made between Groovy 1.7 and 1.8, this syntax no longer works in as many cases as it did before. For example, the following will no longer work:
expect:
object.getAnswer() closeTo(42, 0.001)To avoid such problems, use HamcrestSupport.that:
import static spock.util.matcher.HamcrestSupport.that
...
expect:
that answer, closeTo(42, 0.001)A future version of Spock will likely remove the former syntax and strengthen the latter one.
Frequently Asked Questions (FAQ)
What are Spock’s optional dependencies used for?
Spock runs fine without optional dependencies, hence the term optional. So what are they used for?
-
Objenesis (artifact
org.objenesis:objenesis) is required for mocking classes without default constructors. -
Either ByteBuddy (artifact
net.bytebuddy:byte-buddy) or CGLIB (artifactcglib:cglib-nodep) are required for mocking classes and not just interfaces.
See also Mocking Classes.
Why are there two options (ByteBuddy vs CGLIB) for mocking classes?
The main reason is backwards compatibility. CGLIB came first historically, ByteBuddy was added later. Both libraries basically provide identical features from a Spock user’s perspective.
If you are starting with Spock now, we recommend ByteBuddy as our preferred choice.
CGLIB is in legacy support mode, we will support it as long as the maintenance effort is relatively low. So you may continue to use CGLIB for now if e.g. your tests use it in another context already. If you have no compelling reasons to avoid ByteBuddy, you can just switch from CGLIB to ByteBuddy in an existing project. Your tests should continue to run like before.
Known Issues
Usage of final in a feature method with cleanup #1017
You might run into issues if you use final in your Specification.
Groovy 2.5 introduced a final checker which broke previously compiling code.
tl;dr: Do not use final inside of features if you get compile errors.
Users combining
finaland@CompileStaticorfinaland Spock may see errors from thefinalvariable analyzer. Work is underway to resolve those error messages. You may need to temporarily remove the final modifier in the meantime.
class Broken extends Specification {
def "test"() {
final value = 'hello'
expect:
value.size() > 3
cleanup:
clean value
}
def clean(v) {}
}Will fail with something like.
> Task :compileTestGroovy FAILED
startup failed:
/Users/acme/projects/spock-tests/src/test/groovy/Broken.groovy: 11: The variable [value] may be uninitialized
. At [11:15] @ line 11, column 15.
clean value
This is due to how Spock implements cleanup, by wrapping the whole body in a try-finally block during the AST transformation.
If you look at the compiled code you can see how it was transformed
try {
java.lang.Object value // (1)
java.lang.Throwable $spock_feature_throwable
try {
value = 'hello' // (2)
try {
org.spockframework.runtime.SpockRuntime.verifyCondition($spock_errorCollector, $spock_valueRecorder.reset(), 'value.size() > 3', 8, 9, null, $spock_valueRecorder.record($spock_valueRecorder.startRecordingValue(5), $spock_valueRecorder.record($spock_valueRecorder.startRecordingValue(3), $spock_valueRecorder.record($spock_valueRecorder.startRecordingValue(0), value).$spock_valueRecorder.record($spock_valueRecorder.startRecordingValue(1), 'size')()) > $spock_valueRecorder.record($spock_valueRecorder.startRecordingValue(4), 3)))
}
catch (java.lang.Throwable throwable) {
org.spockframework.runtime.SpockRuntime.conditionFailedWithException($spock_errorCollector, $spock_valueRecorder, 'value.size() > 3', 8, 9, null, throwable)}
finally {
}
}
catch (java.lang.Throwable $spock_tmp_throwable) {
$spock_feature_throwable = $spock_tmp_throwable
throw $spock_tmp_throwable
}
finally {
try {
this.clean(value) // (3)
}
catch (java.lang.Throwable $spock_tmp_throwable) {
if ( $spock_feature_throwable != null) {
$spock_feature_throwable.addSuppressed($spock_tmp_throwable)
} else {
throw $spock_tmp_throwable
}
}
finally {
}
}
this.getSpecificationContext().getMockController().leaveScope()
}
finally {
$spock_errorCollector.validateCollectedErrors()
}-
Here it moved the variable declaration outside of the
try-finallyblock -
Here it tries to initialize the field
-
Here it is passed to cleanup
The catch-22 is that the variable must be declared outside of the try-finally block, to be available in the finally,
but for the variable initialization to be covered by the cleanup it must be initialized inside the try block.
This works fine for normal variables, but final variable can only be initialized when they are declared.
Using Traits with Specifications
Traits on Specifications are not supported by Spock, some use-cases might work while others don’t. This is due to how groovy implements traits and AST transformations.
Traits are not officially compatible with AST transformations. Some of them, like @CompileStatic will be applied on the trait itself (not on implementing classes), while others will apply on both the implementing class and the trait. There is absolutely no guarantee that an AST transformation will run on a trait as it does on a regular class, so use it at your own risk!
Groovy version compatibility
By default, Spock can only be used with the Groovy version it was compiled with. It means that Spock 2.0-groovy-2.5 can only executed with Groovy 2.5.x, 2.0-groovy-3.0 with 3.0.x, etc. That restriction was introduced to help users find an appropriate Groovy variant and limit number of reported invalid issues caused by the incompatibilities between the major Groovy versions.
However, occasionally it might be useful to be able to play with the next (officially unsupported) Groovy version, especially that usually, in the majority of cases, it should just work fine. Starting with Groovy 2.0 that restriction has been relaxed in the Spock SNAPSHOT versions. In addition, the early adopters can implicitly disable that check - also in the production versions - providing the system property -Dspock.iKnowWhatImDoing.disableGroovyVersionCheck=true. Please bear in mind, however, that it is completely unsupported and might lead to some unexpected errors.